
Scale Labs has launched the Refactoring Leaderboard, the final pillar of SWE Atlas, its research suite for evaluating AI coding agents on software engineering work that goes beyond isolated coding prompts. SWE Atlas is designed to measure agents across the software development cycle, including codebase comprehension, test writing, and now complex refactoring.
The new leaderboard focuses on whether AI agents can restructure production-style code while preserving existing behavior. Instead of asking models to solve small programming tasks, Scale Labs tests how they operate inside larger repositories, understand existing architecture, modify multiple files, keep tests passing, and clean up stale artifacts after a refactor. According to the attached research, SWE Atlas Refactoring tasks require about twice as many lines of code changes and 1.7x more file edits than SWE-Bench Pro tasks, making the benchmark a higher-pressure test of multi-file software engineering work.
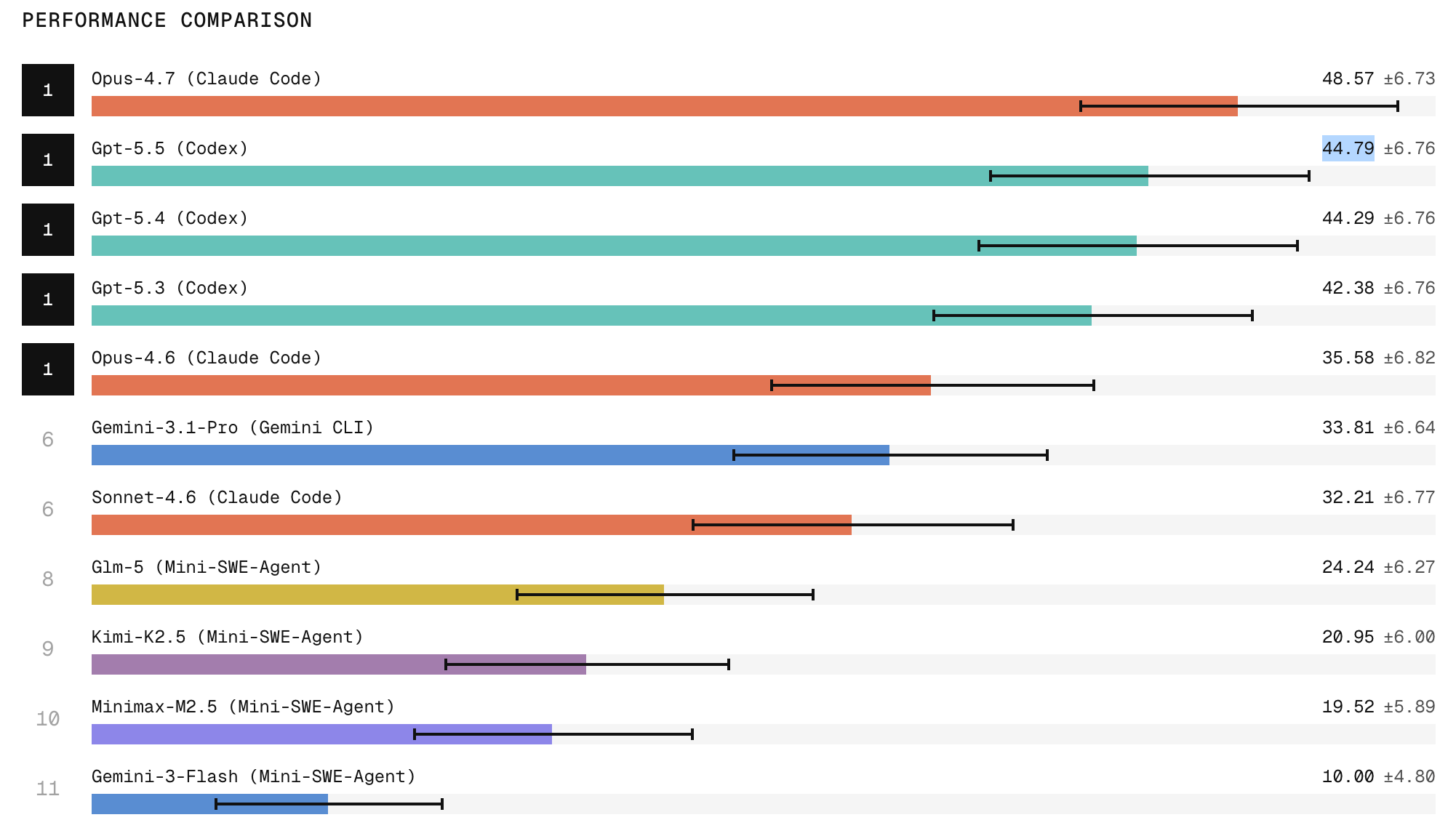
Claude Code with Opus 4.7 ranks first on the Refactoring Leaderboard, with the research showing it produces the strongest refactors among tested agents. ChatGPT 5.5 follows in second place. The results also show a wide gap between frontier closed models and open models, with open-weight systems trailing on tasks that require broad repository exploration, structural edits, and behavior preservation.
The benchmark covers four types of refactoring work:
- Decomposing monolithic implementations
- Replacing weak interfaces with typed or cleaner abstractions
- Extracting duplicated or misplaced logic into shared modules
- Relocating code to improve module boundaries
Each task is evaluated through test passing and a rubric-based review that checks code maintainability, artifact cleanup, anti-pattern avoidance, and documentation maintainability.
Refactoring is hard, even for frontier agents. SWE Atlas refactors are 2× the size of SWE-Bench Pro and 30× SWE-Bench Verified by lines changed. pic.twitter.com/NxlfYyJtQn
— Scale Labs (@ScaleAILabs) May 7, 2026
One of the main findings is that models can often make a refactor pass tests, but still fail engineering-quality checks. The research notes that agents frequently leave dead code, stale imports, duplicated implementations, outdated comments, or missed call sites. This “cleanup” problem becomes a clear separator between models that can complete a visible task and models that can produce production-grade changes.
Reliability remains the deeper issue. Scale Labs says that when models attempt the same task three times, they are two to three times more likely to succeed once than to succeed across all three attempts. That means a model may appear capable in a single run while still being too inconsistent for unattended production workflows. In this framing, the leaderboard is not only measuring peak capability but also whether an agent can be trusted to repeat that capability under similar conditions.
Scale Labs positions SWE Atlas as a research framework for treating AI agents more like software engineers than code generators. The company is using the suite to test work that resembles real engineering workflows, where an agent must inspect a codebase, infer design constraints, make coordinated edits, and avoid regressions. The Refactoring Leaderboard completes that suite by targeting one of the hardest parts of engineering automation: changing structure without changing behavior.
AI pretenders vs. AI contenders. It's those who still haven’t realized reliability is the product vs. those who can deliver reliability and outcomes. That's what the enterprise AI race comes down to. Here's a note I sent the Scale team this week. https://t.co/dq5BlROaE3
— Jason Droege (@jdroege) May 6, 2026
Jason Droege, Scale Labs’ CEO, said reliability is the central hurdle for AI agents. The new Refactoring Leaderboard supports that point by showing that model capability and consistency are not moving at the same pace. The strongest models are improving, with Opus 4.7 leading the current results, but Scale’s data suggests that agents still need stronger repeatability, cleaner artifact removal, and deeper codebase understanding before they can operate independently in production engineering environments.





