
A major technology company has introduced speculative decoding for its Gemma 4 LLMs, addressing the longstanding challenge of inference latency caused by memory-bandwidth limitations. This new release targets developers building applications that depend on low-latency AI outputs, such as chatbots, coding assistants, autonomous agents, and mobile applications that run entirely on-device.
— Google for Developers (@googledevs) May 5, 2026
Speculative decoding pairs a high-capacity main model, like Gemma 4 31B, with a lighter drafter model (MTP), enabling the system to draft several future tokens in advance. The main model then verifies these in parallel, allowing for the acceptance of an entire sequence in the time it would typically take to generate a single token.
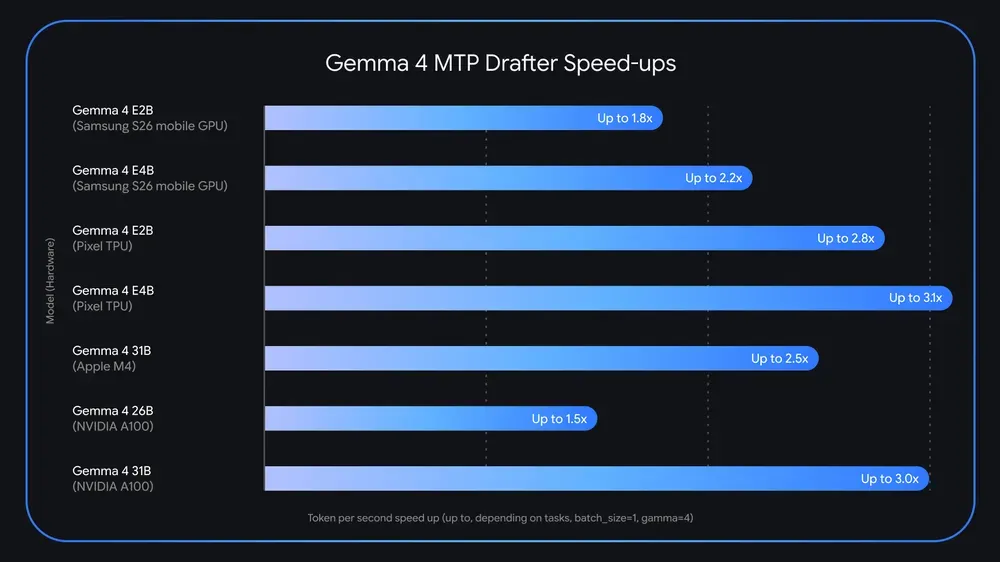
This feature is available for developers using Gemma 4 models, including the 26B MoE and 31B Dense variants, and is supported on consumer GPUs and edge devices. The primary motivation is to reduce AI inference times, making advanced language models practical for resource-constrained environments while maintaining output quality.
Technically, developers benefit from faster local development and improved on-device performance, with no compromise in reasoning or accuracy since the draft is always checked by the main model. Early technical feedback highlights the substantial speed improvements for real-time applications and edge deployments, positioning the company as a leader in AI efficiency for both local and distributed computing environments.





