Condense.chat has opened public access to a context-compression proxy for coding agents, a system that sits between an agent and the upstream model, shrinking each request before billing. It targets a line item most teams never inspect. In a working agent loop, the model is re-sent the system prompt plus the whole conversation on every turn, so by the middle of a long session, it has re-read the same early context hundreds of times. Across twelve real coding sessions and 18,333 assistant turns, Condense puts cache reads at 67.7 percent of a typical bill, the cost the proxy is built to remove.
We're giving you 100M free tokens to prove your agent is wasting context.
— condense.chat (@densechat) July 3, 2026
Most of what your agent sends upstream is dead weight. We built state-of-the-art compaction to strip it, and today we published the receipts.
One real session, run to full depth, benchmarked against… pic.twitter.com/40ZdASrHoj
The proxy runs two compression models in sequence. Helene 1, an extractive model, scores every token and keeps the survivors verbatim as a strict subset of what the agent saw, stripping content before it reaches cache. Adeline 1, a diffusion-based rewriter, takes settled agent loops the session has moved past and packs each into a short summary that holds intents, file paths, identifiers, errors, and code, landing at roughly 9 percent of the original tokens. The skeleton, meaning the system prompt, user messages, final answers, and paired tool calls with their results, is preserved byte for byte and never rewritten. Only the aged interior of past loops is stripped or packed, so the working set the model is reasoning over stays raw.
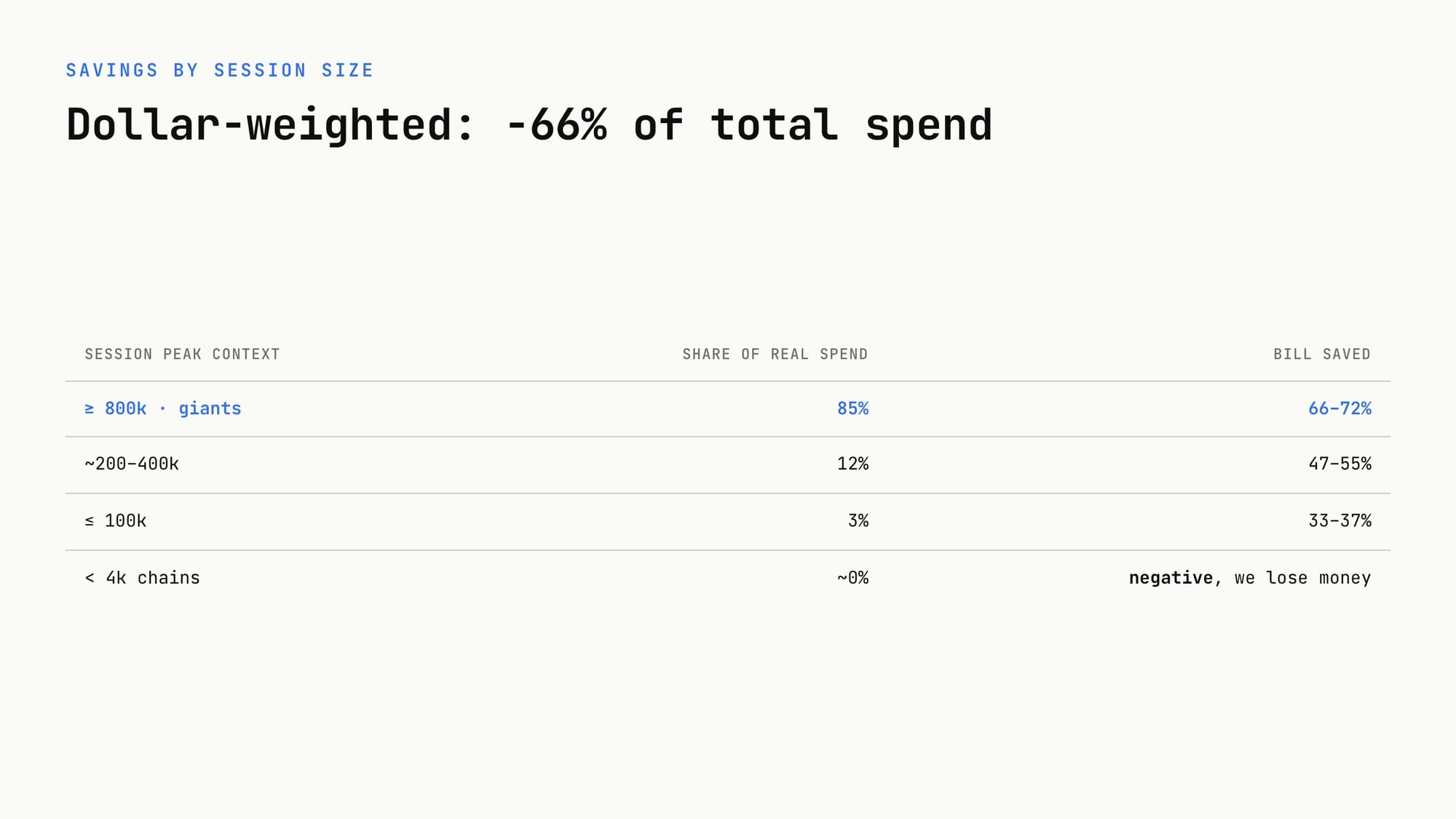
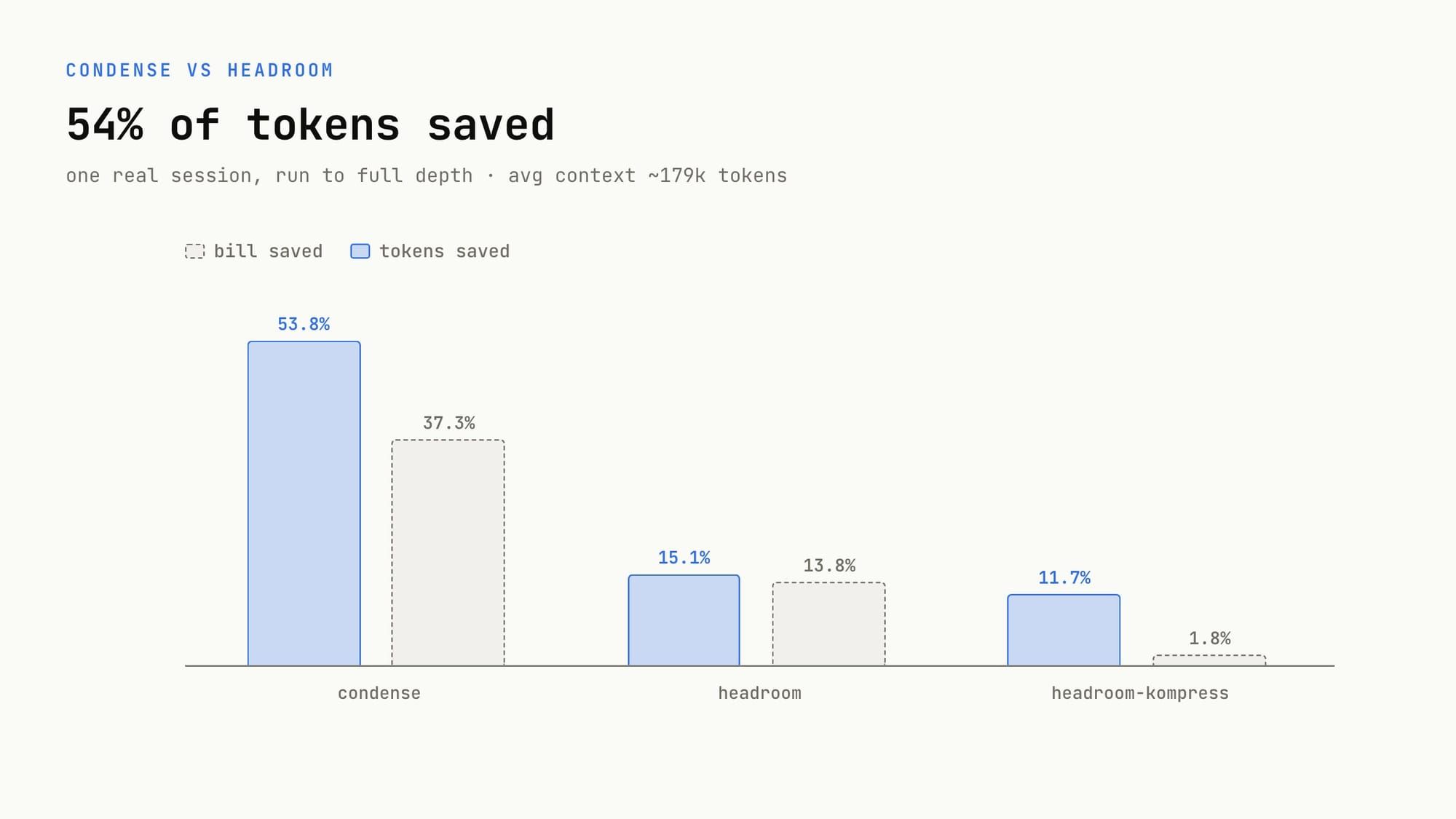
On one real session replayed to 938 turns, Condense reports the bill falling 72.3 percent, taking a Sonnet run from 154 dollars to 43 and an Opus run from 771 to 214, with dollar-weighted savings across every session size near 66 percent. The company states the effect compounds with depth, since a larger context means a larger frozen prefix and a smaller slice of history re-read each turn, passing 53 percent on sessions with chains above 400,000 tokens. Answer faithfulness against uncompressed transcripts is reported at 94.2 percent.

Setup is a single command that drops the harness in front of an existing agent with no key swap, and the drop-in API speaks both the OpenAI and Anthropic SDKs, so a team can point its base URL at a provider route and keep its own key. The proxy currently drives Claude Code, Codex, and OpenCode across macOS, Linux, and Windows. It is aimed at developers running agent workflows at scale, where re-read costs dominate, and the deepest sessions incur the largest bills.
Condense is giving TestingCatalog readers 100M saved tokens.
Condense is built by engineers with backgrounds shipping large-model infrastructure at Nord Security, Kilo Health, and Nexos AI. The full measurement pipeline is published as an open harness on GitHub, including the cost-split study and the replay tool, so the figures can be recomputed without a key.





