SenseTime's SenseNova team released U1 on April 28, 2026 - a family of multimodal models built on a rethought architecture called NEO-Unify. Two models are now publicly available with weights on HuggingFace: SenseNova-U1-8B-MoT(dense MoT backbone) and SenseNova-U1-A3B-MoT (~3B activated, MoT backbone). Both are released under Apache 2.0, which permits commercial use and allows weights to be pulled and self-hosted.
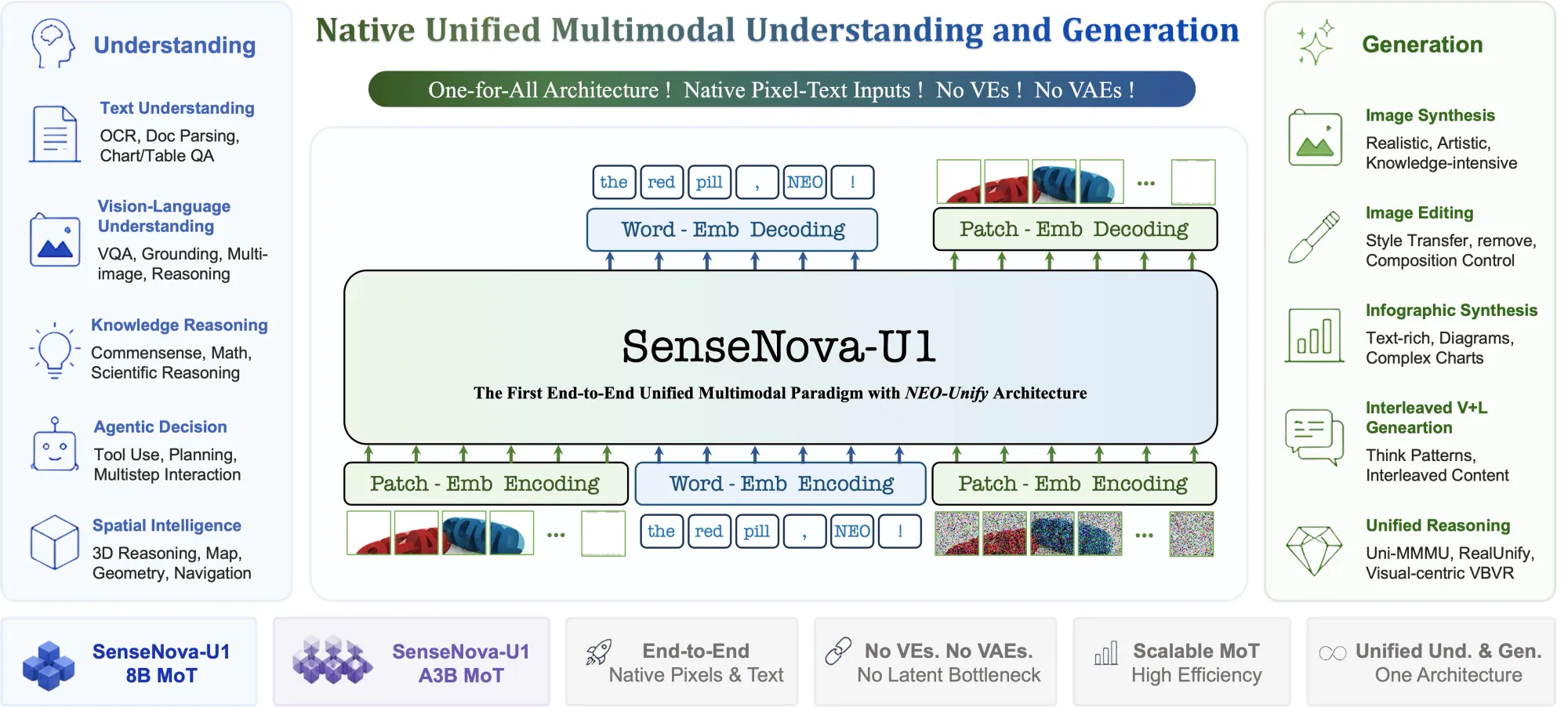
NEO-Unify drops both the visual encoder and variational autoencoder that have anchored nearly every modern multimodal model. Instead of routing images through a separate perception stack and text through a language model, then bridging them with adapters, the system models language and visual information end-to-end as a unified compound. Pixel-to-word information is inherently and deeply correlated from the ground up.
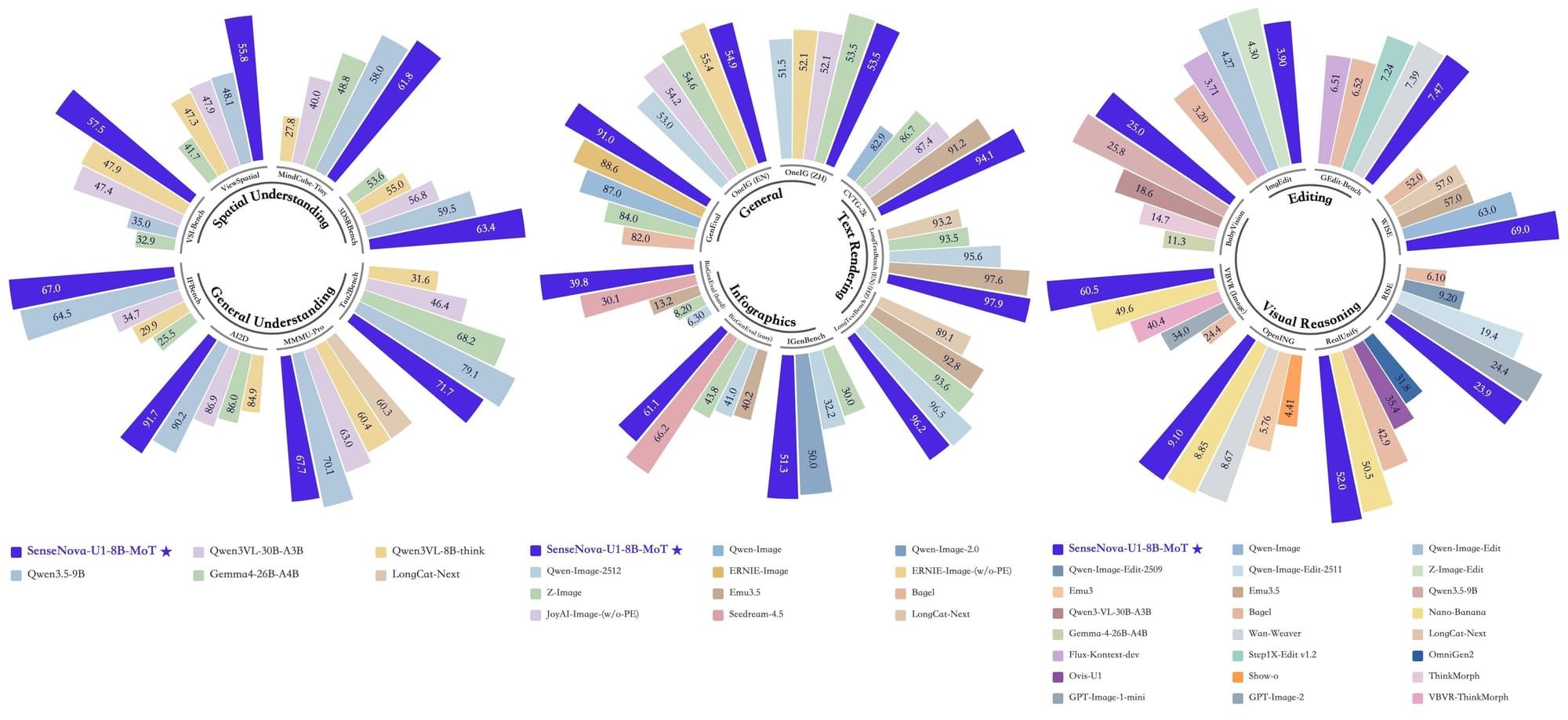
𝗦𝗢𝗧𝗔 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 pic.twitter.com/NAprO9zm5w
— SenseTime (@SenseTime_AI) April 28, 2026
At the core are native MoTs (Mixture of Tokens), which enable the model to reason across modalities efficiently and with minimal conflict. Rather than routing computation between expert modules (as in MoE architectures), the model operates on a unified token space that spans both modalities natively.
The result: a single model that handles understanding, reasoning, and generation in one continuous flow, without tool-switching, adapter translation, or external pipelines.
Neither standard multimodal understanding models nor dedicated image generators can produce this kind of coherent text-image interleaved output in a single continuous pass.
The infographic and document generation capability closes a gap that previously required expensive closed-source pipelines. U1 targets PPT decks, structured posters, and data-heavy diagrams at roughly one-tenth of the cost of closed-source alternatives, while running fully open on infrastructure teams control directly. For B2B builders and visual content workflows operating at scale, the cost delta is the practical unlock.
Native interleaved generation U1 generates coherent interleaved text and images in a single pass, practical guides, travel diaries, and educational walkthroughs that blend clear prose with generated visuals. Neither standard language models nor image generators can produce this kind of output in one continuous flow. Beyond generation, U1 handles general VQA and agentic visual understanding, all folded into the same unified model.
Test the new SenseNova-U1 models!
SenseTime is a Hong Kong-listed AI company founded in 2014, with roots in computer vision research. The SenseNova model family launched in 2023 and has progressed through several generations, with SenseNova 6.5 in mid-2025 pushing toward early multimodal fusion at the encoder level. The U1 release marks a further step: the encoder layer is gone entirely, replaced by a native unified representation space.
SenseTime reported 2025 revenue of RMB 5.01 billion, up 32.9% year-on-year, while continuing to narrow annual losses and invest in large-model infrastructure.





