
OpenSquilla has released its first public version, a self-hostable, open-source AI agent runtime built around a single premise: most agent deployments spend tokens they do not need to spend, and the frameworks running them offer no real mechanism to stop it. The project targets developers and teams running agents for sustained, long-horizon work, where token bills compound across sessions and context management becomes the operational ceiling before capability does.
In a local test run against the gateway, three prompts spanning a simple factual query, a medium-complexity technical summary, and a full competitive analysis of AI agent frameworks processed a combined 279,762 tokens for a total session cost of $0.0094. Of those tokens, 222,848 were served from cache, roughly 80% of all input tokens, a direct result of OpenSquilla reusing context across turns rather than reloading it fresh on every call. The routing classifier was active and logging gate decisions per query throughout the session. The security sandbox runs in a no-op mode on Windows by design, with full syscall-level isolation available in production deployments on Linux.
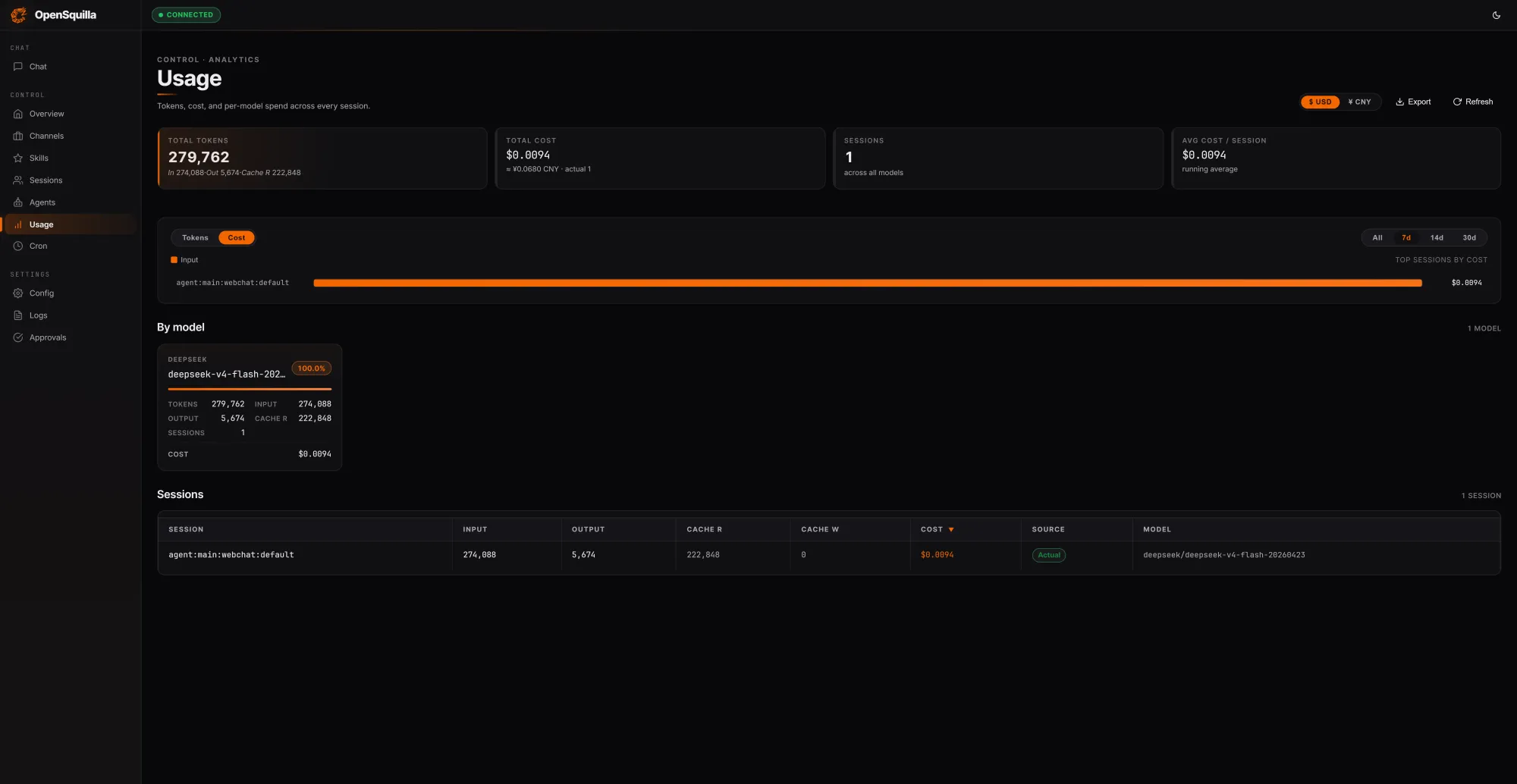
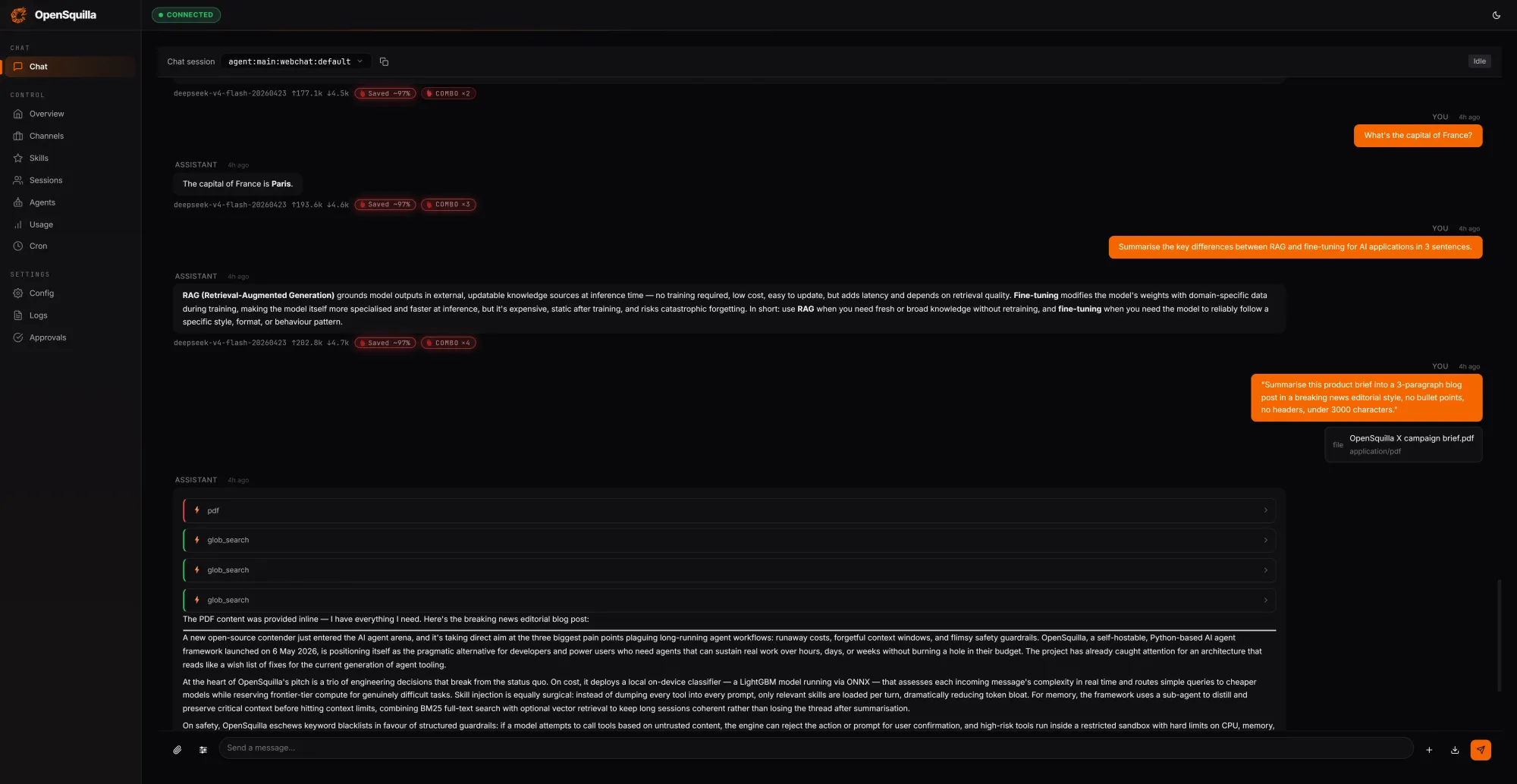
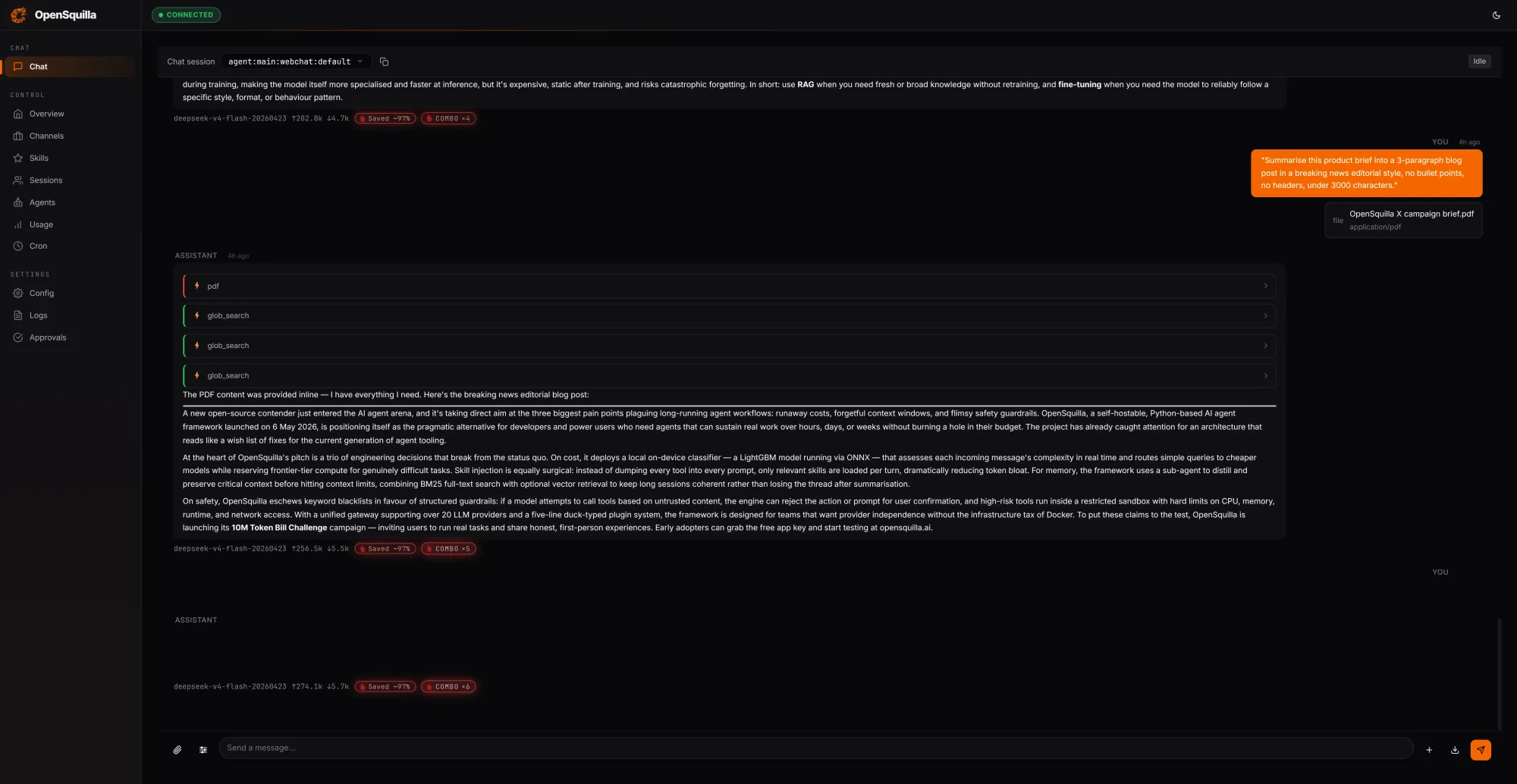
The cost case rests on a coordinated stack of routing strategies rather than a single dial. An ML classifier combines hand-crafted signals, including message length, presence of code blocks, and keyword patterns, with embedding-based semantic features to score each incoming request by complexity. Simple queries route to cheaper models. Deep reasoning is disabled for lightweight tasks, so teams are not paying for extended chain-of-thought on a trivial prompt. Skills load on demand rather than being packed wholesale into every context window. According to OpenSquilla's own benchmarks, the combined effect of these strategies cuts token spend by 60 to 80 percent compared to a flat, single-model configuration. Quota hooks and per-call cost tracking are built in from the start, so overspend can be caught and throttled automatically.
Memory is handled through a four-tier cognitive architecture modeled on how human memory is structured rather than how most agent frameworks approximate it:
- Working memory holds the current task.
- Episodic memory captures experience and causal relationships across sessions.
- Semantic memory stores persistent facts and rules.
- Raw memory functions as an audit and retraining base.
Retrieval combines vector-semantic search with BM25 full-text search, running in parallel, with embeddings processed locally via bundled ONNX inference, keeping data on-device without requiring an external provider. A hot memory promotion mechanism automatically surfaces frequently recalled items, while a temporal decay function lets dated memories fade unless explicitly marked as evergreen. Every 24 hours, a consolidation pass restructures scattered memories into denser, more organised knowledge. The project calls this Memory Dream Consolidation, drawing the parallel to how sleep consolidates human memory.
On security, OpenSquilla uses syscall-level isolation rather than wrapping Docker. Three policy tiers control how tools execute:
- Standard operations run directly.
- Strict operations require sandbox approval.
- Locked operations must pass human review before proceeding.
The sandbox uses Bubblewrap on Linux and Seatbelt on macOS to isolate code execution from the real filesystem, without a container runtime dependency. A denial ledger pauses the agent after three consecutive rejections, blocking brute-force attempts to push through restricted actions. Prompt injection vectors are closed by XML-escaping all skill metadata and tool results before they reach the model.
Test it out for yourself at OpenSquilla!
The architecture is described as a microkernel: a core orchestrator of roughly 100 lines that handles state management and pipeline sequencing, while every capability from LLM providers and memory backends to channel adapters and tool integrations runs as a pluggable module in user space. Writing a plugin requires a five-line duck-typed class with no base class, SDK package, or manifest file. The gateway serves over ten built-in channels, including Slack, Discord, Telegram, MS Teams, Matrix, and several enterprise messaging platforms. The runtime ships at v0.1.0 under Apache-2.0, requires Python 3.12+, and is available for self-hosting on GitHub. The team is running a 10M Token Bill Challenge alongside the release, offering free token credits for developers who want to benchmark the framework against their current agent infrastructure costs.





