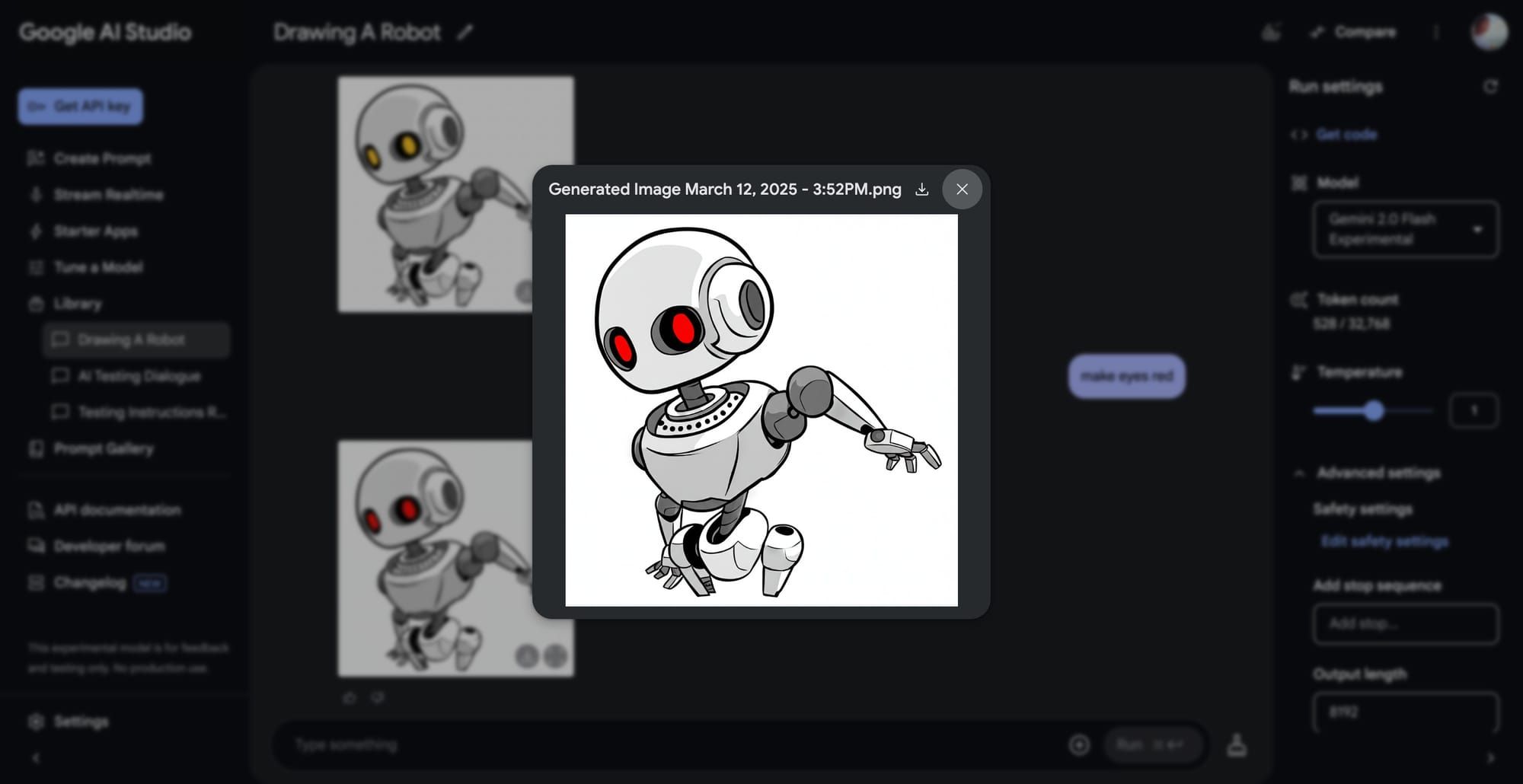
Google has quietly rolled out experimental multimodal image output capabilities for its Gemini 2.0 Flash model in AI Studio, making it the first major lab to offer such features ahead of competitors like OpenAI and xAI. This update introduces native image generation, image editing without requiring regeneration, and a new "Output Format" setting allowing users to toggle between "text" and "image and text" outputs.
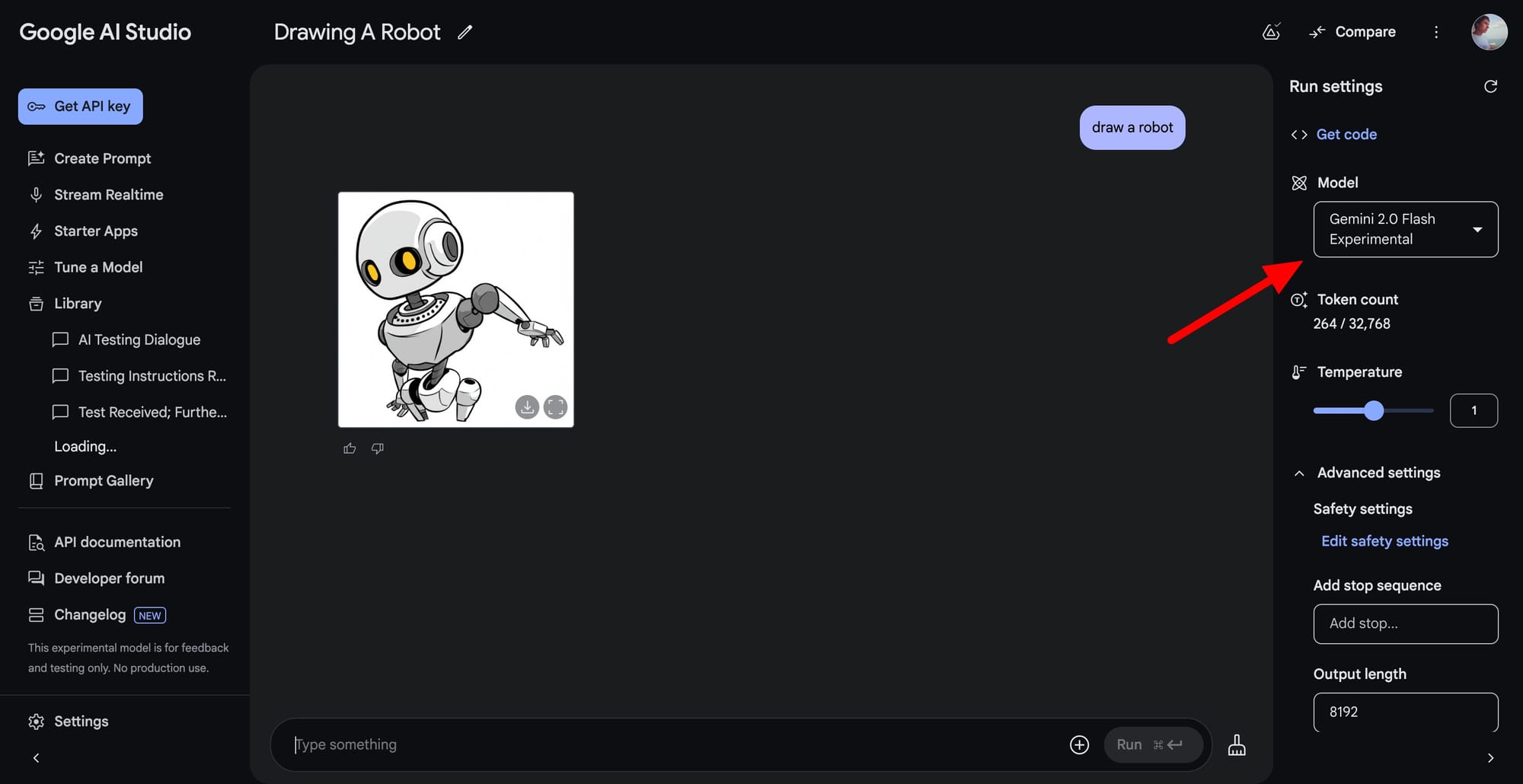
Native image output
Gemini 2.0 Flash now supports multimodal outputs, enabling users to generate images alongside text or edit existing images conversationally. This includes advanced editing capabilities where users can refine specific aspects of an image without generating a completely new one. For example, users can modify the background or other elements of an image by providing targeted instructions. All generated images include SynthID watermarks to ensure authenticity and reduce misinformation risks.
Native image output on AI Studio is a very different experience from what you have been trying before.
— TestingCatalog News 🗞 (@testingcatalog) March 12, 2025
A big step for image gen 👀 https://t.co/TJlUwIxEej pic.twitter.com/Z2tVmCTKDl
Additionally, the "Output Format" setting lets users switch between text-only responses or combined text and image outputs, providing greater flexibility depending on their use case.
About AI Studio
Google DeepMind has been steadily advancing its Gemini AI model family since its initial release in December 2024. Gemini 2.0 Flash builds on the success of earlier versions by introducing multimodal capabilities, faster processing speeds, and improved spatial reasoning. The company has positioned this model for developers in AI Studio and Vertex AI, focusing on agentic AI features such as tool calling and real-time multimodal applications.
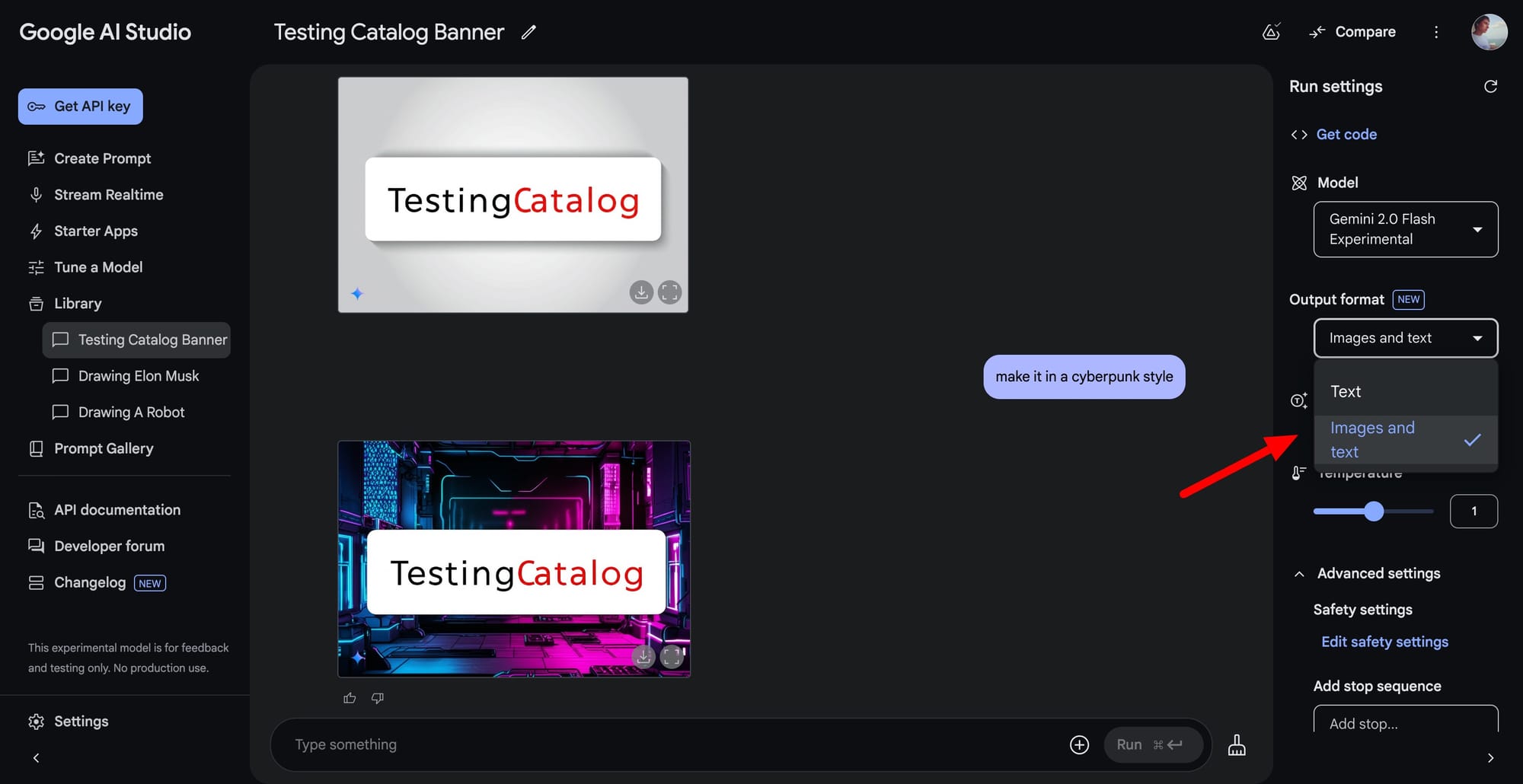
Recent updates to Gemini have emphasized creative tools like localized artwork creation and detailed image editing, catering to industries such as design, marketing, and content creation. This experimental rollout aligns with Google's broader strategy of pioneering safe and scalable generative AI technologies





