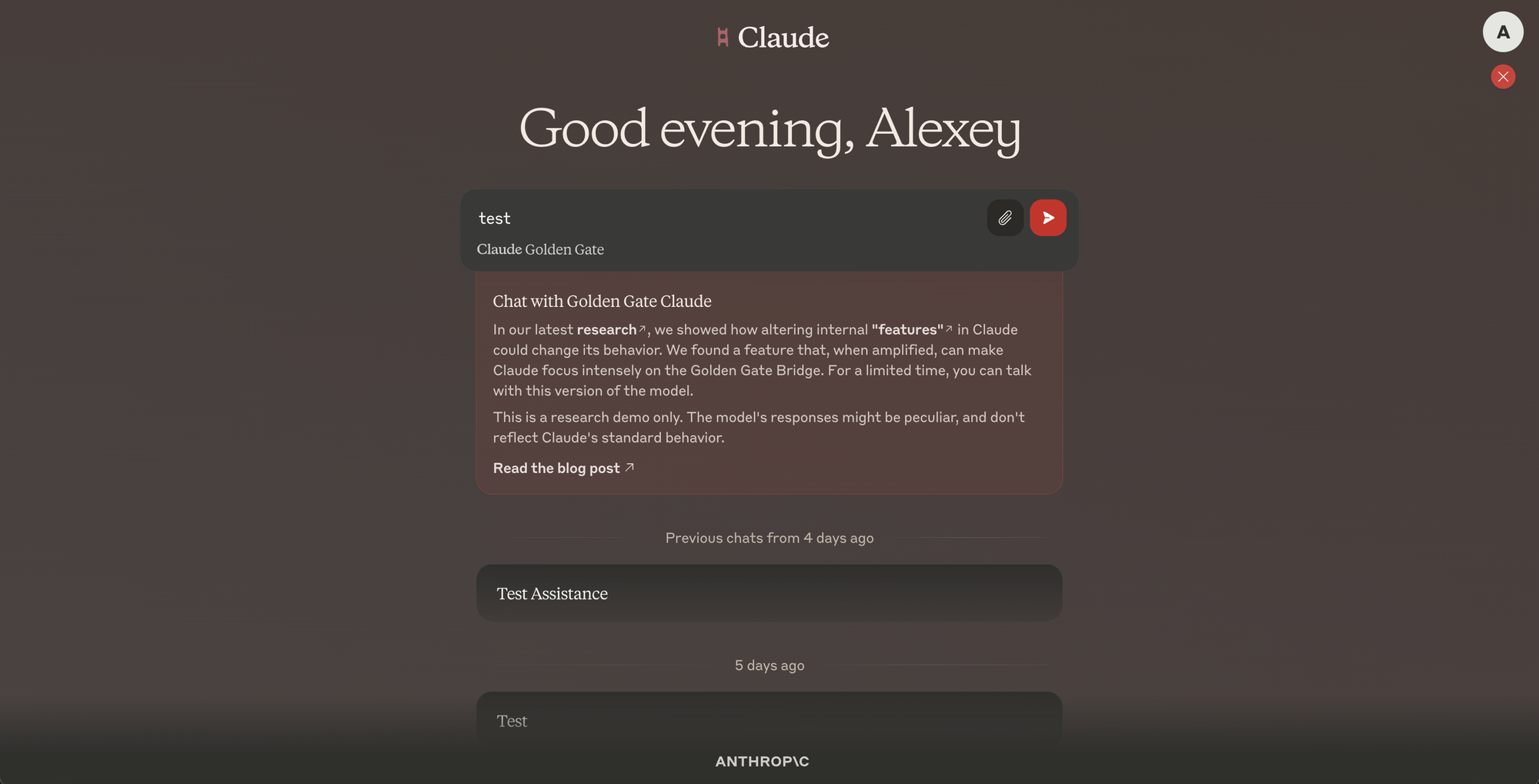
Anthropic released a research document on May 23, 2024, with the title "Golden Gate Claude," concentrating on the comprehensibility of large language models, notably their Claude 3 Sonnet AI model. The study sought to decode Claude by pinpointing and manipulating distinct concepts or "features" that trigger within the model's neural network upon encountering relevant text or images. An illustrative example provided was the feature linked to the Golden Gate Bridge, revealing how particular neuron combinations trigger when coming across references or visuals of the bridge. Adjusting the strength of these feature activations alters Claude's replies, drawing them closer to the Golden Gate Bridge theme, even in disjointed scenarios. This adjustability was highlighted through "Golden Gate Claude," a variation of the model made available for public use on the claude.ai website, permitting visitors to witness changes in behavior by utilizing the model via a specific emblem on the site.
This week, we showed how altering internal "features" in our AI, Claude, could change its behavior.
— Anthropic (@AnthropicAI) May 23, 2024
We found a feature that can make Claude focus intensely on the Golden Gate Bridge.
Now, for a limited time, you can chat with Golden Gate Claude: https://t.co/uLbS2JNczH pic.twitter.com/WHmoi2AmoR
To experience this phenomenon, visitors can go to claude.ai, select the Golden Gate emblem, and use "Golden Gate Claude," leading to replies predominantly centered around the Golden Gate Bridge. This distinct interaction serves as a clear demonstration of the research's objectives: to illustrate the importance of interpretability in comprehending intricate AI models and to offer insights into AI behavior modification by altering feature activations.
The Golden Gate Claude initiative underscores a fresh method of probing and modifying the internal mechanics of AI models, providing a concrete example of how meticulous interpretability efforts can result in a more profound understanding of AI functionalities. This examination not only navigates the intricate web of AI model features but also presents a strategy to directly modify AI behavior, contributing essential insights into the potential to direct AI response patterns through precise feature adjustment.





