Anthropic has launched Claude Opus 4.5, positioning it as its most capable AI model to date. The release is targeted at developers, enterprises, teams, and individual users who require advanced AI for coding, research, and business applications. Claude Opus 4.5 is now generally available through Anthropic’s apps, API, and on all major cloud platforms, making it accessible to a wide audience. The model is priced at $5 for input and $25 for output per million tokens, a notable reduction compared to previous Opus models, allowing broader adoption.
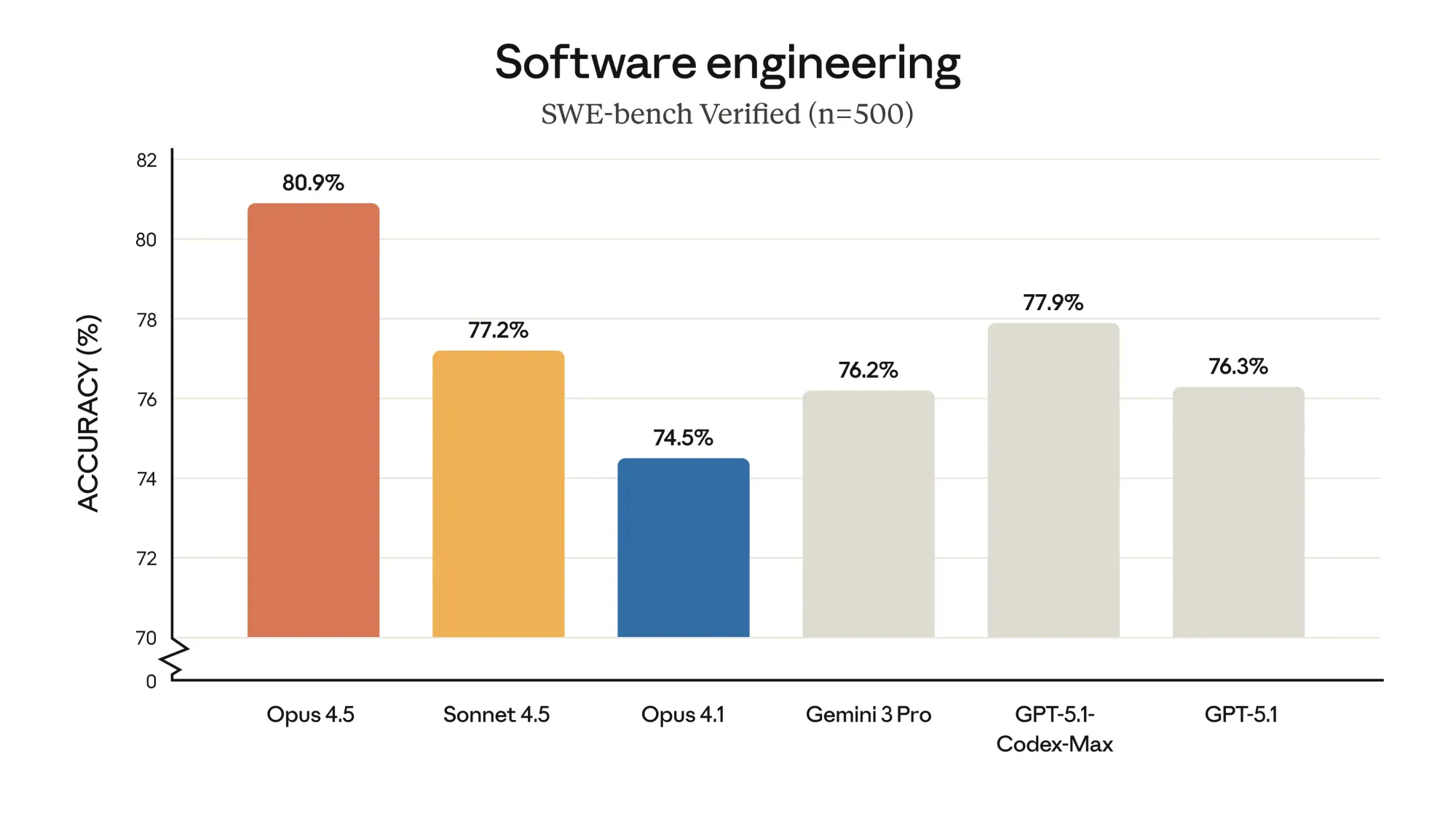
Claude Opus 4.5 delivers significant technical improvements, including higher accuracy in software engineering tasks, advanced vision, reasoning, and mathematical capabilities. Benchmarks show it outperforms both its predecessor, Sonnet 4.5, and other leading models on complex coding, agentic workflows, and multi-step reasoning. It offers a new effort parameter in the API, enabling users to control the balance between speed and depth of analysis, with the model able to use up to 76% fewer tokens for comparable tasks. The model demonstrates creative problem-solving and improved alignment, showing reduced prompt injection vulnerability and improved reliability in agentic and autonomous tasks.
Claude Code is now available in our desktop app.
— Claude (@claudeai) November 24, 2025
Run multiple sessions in parallel: code, research, and update work all at once.
And Plan Mode gets an upgrade with Opus 4.5—Claude asks clarifying questions upfront, then works autonomously. pic.twitter.com/r0z9ZXJjNs
Anthropic, the company behind Claude Opus 4.5, continues to focus on AI safety and robust alignment as core priorities. This release extends their platform’s capabilities by updating Claude, Claude Code, and related consumer apps, with new features such as long context handling, improved Excel and Chrome integration, and expanded desktop functionality for coding agents. Early feedback from industry testers and enterprise partners highlights Claude Opus 4.5’s efficiency, reliability, and cost-effectiveness, with many noting it now surpasses internal benchmarks and supports deeper, longer tasks across diverse use cases.





