OpenAI jolts the AI landscape with GPT-OSS, its first open-weight language models since GPT-2. Two variants land: a 120-billion-parameter model that rivals the closed o4-mini while running on a single 80 GB GPU, and a 20-billion-parameter sibling that fits into 16 GB of memory. Both ship under Apache 2.0 and are already mirrored on Hugging Face, AWS, Azure, and Databricks for immediate download.
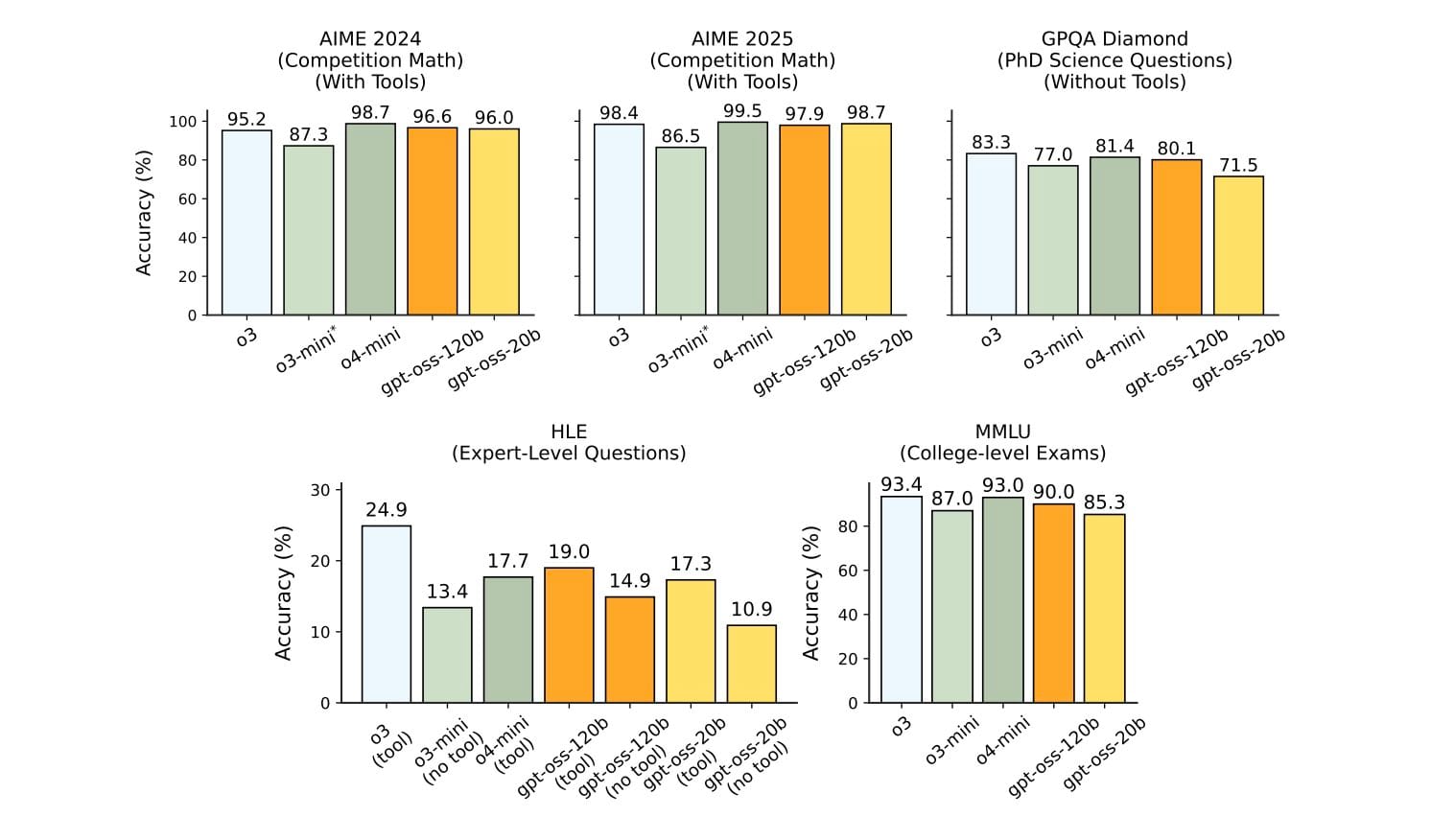
The Transformer mixture-of-experts design lights up only four experts per token, delivers 128 k context, structured outputs, and function calling, and slots into agent workflows via the Responses API. Internal benchmarks place the larger model above o3-mini on MMLU, Codeforces, and tool-use evaluations, with the smaller one matching or edging past o3-mini despite its lean footprint.
Early partners AI Sweden, Orange, and Snowflake are hosting the weights on-prem for data-sensitive workloads and rapid sector-specific fine-tuning. Observers frame the move as OpenAI’s reply to Llama 3 and Mixtral, giving developers a top-tier model they can run locally without licensing fees.
A 50-page system card plus external safety audits accompany the release, detailing CBRN data filtering, adversarial fine-tuning tests, and Preparedness Framework reviews. After years of withholding weights over safety worries, the company reverses course; leadership argues that controlled openness can now coexist with frontier-level reasoning, marking a new chapter in its product strategy.





