
Mistral has introduced Voxtral, its first family of open-source audio models for businesses, released on July 15, 2025. These models enable transcription, comprehension, and action-oriented interactions with speech. Two variants are available: Voxtral Small (24 B parameters) for production-scale deployments, and Voxtral Mini (3 B parameters) tailored for edge and local environments. Additionally, an API-only option, Voxtral Mini Transcribe, focuses exclusively on transcription and is priced at less than half the cost of competing offerings.
Voxtral Small, built on Mistral’s LLM backbone (Mistral Small 3.1), supports 30-minute audio processing and extends language understanding up to 40 minutes. It offers multilingual support in English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian; plus features like querying summaries or converting voice to API calls or function executions. Complementing this, Voxtral Mini delivers a compact footprint ideal for low‑resource deployment scenarios, with a transcription‑only option offering Whisper‑level performance at competitive pricing.
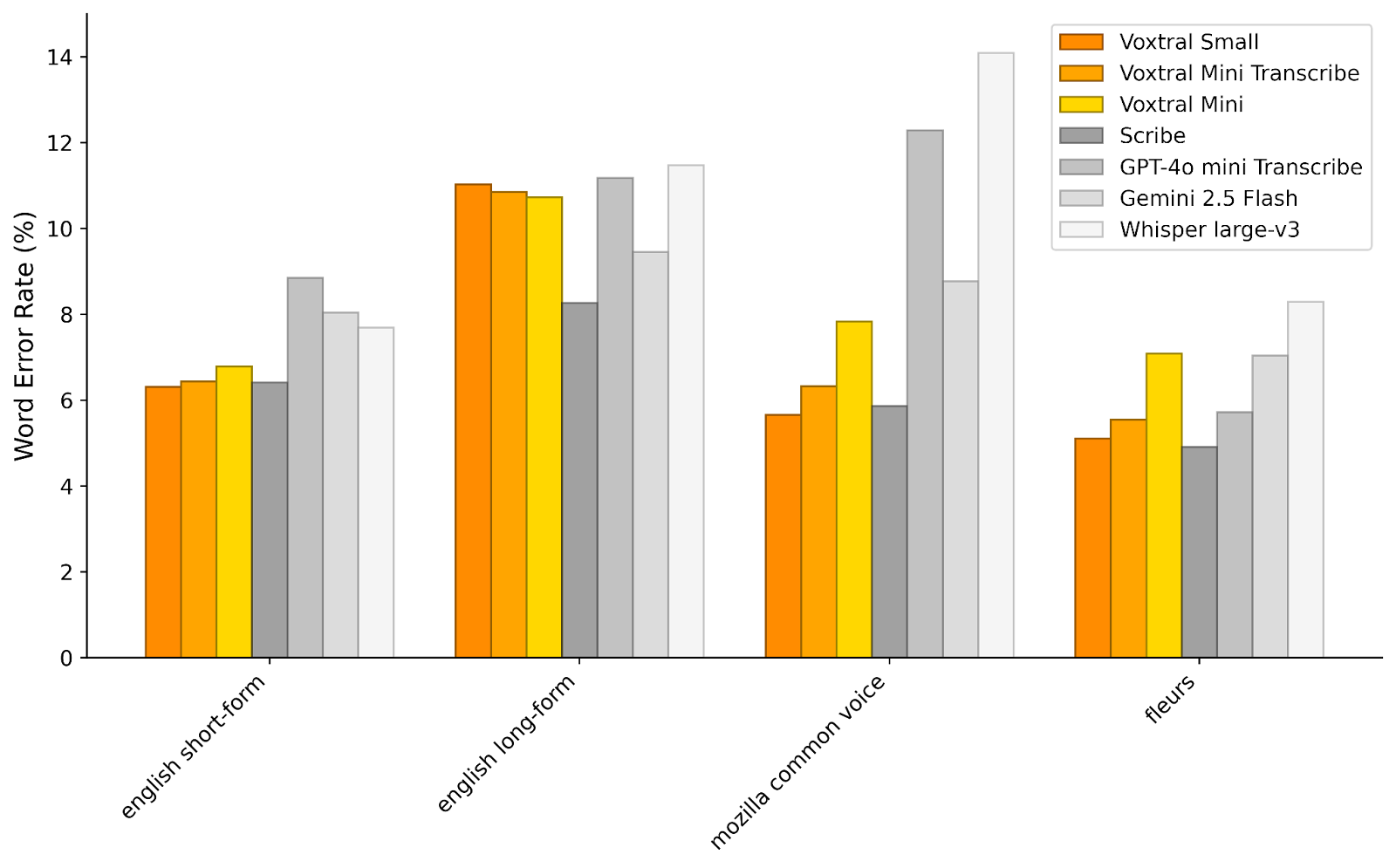
Mistral is positioning Voxtral as a bridge between low‑cost open systems with poor comprehension and closed proprietary solutions that are expensive and restrictive. The open weights allow businesses to deploy in-house, control infrastructure, and reduce expenses, starting at USD 0.001 per minute via its API, with models available on Hugging Face and through Mistral’s “Le Chat” interface.
This launch closely follows the introduction of Magistral in June 2025, Mistral’s first reasoning model. The company is emerging as one of Europe’s pioneering open‑source AI leaders, backed by strong investor interest.

For enterprises, Voxtral introduces a robust, flexible and cost‑efficient tool to integrate speech intelligence into applications, offering multilingual support, production‑grade performance, local‑deployment options, and API‑based usage.
Mistral is a Paris‑based AI startup known for its open‑source models (e.g., Mistral Small, Mixtral and Magistral) released since early 2024. With backing that includes a possible billion‑dollar raise, it focuses on pushing open‑weight models that can rival big‑tech AI systems. Voxtral represents its first foray into audio intelligence, addressing developers’ needs for transparent, low‑cost, and deployable speech AI solutions.
Innovation stems from its sequence of open‑source releases: Pixtral for multimodal tasks, Magistral for reasoning, and now Voxtral for speech, each contributing to a stack that enables developers to build comprehensive AI applications end to end.





