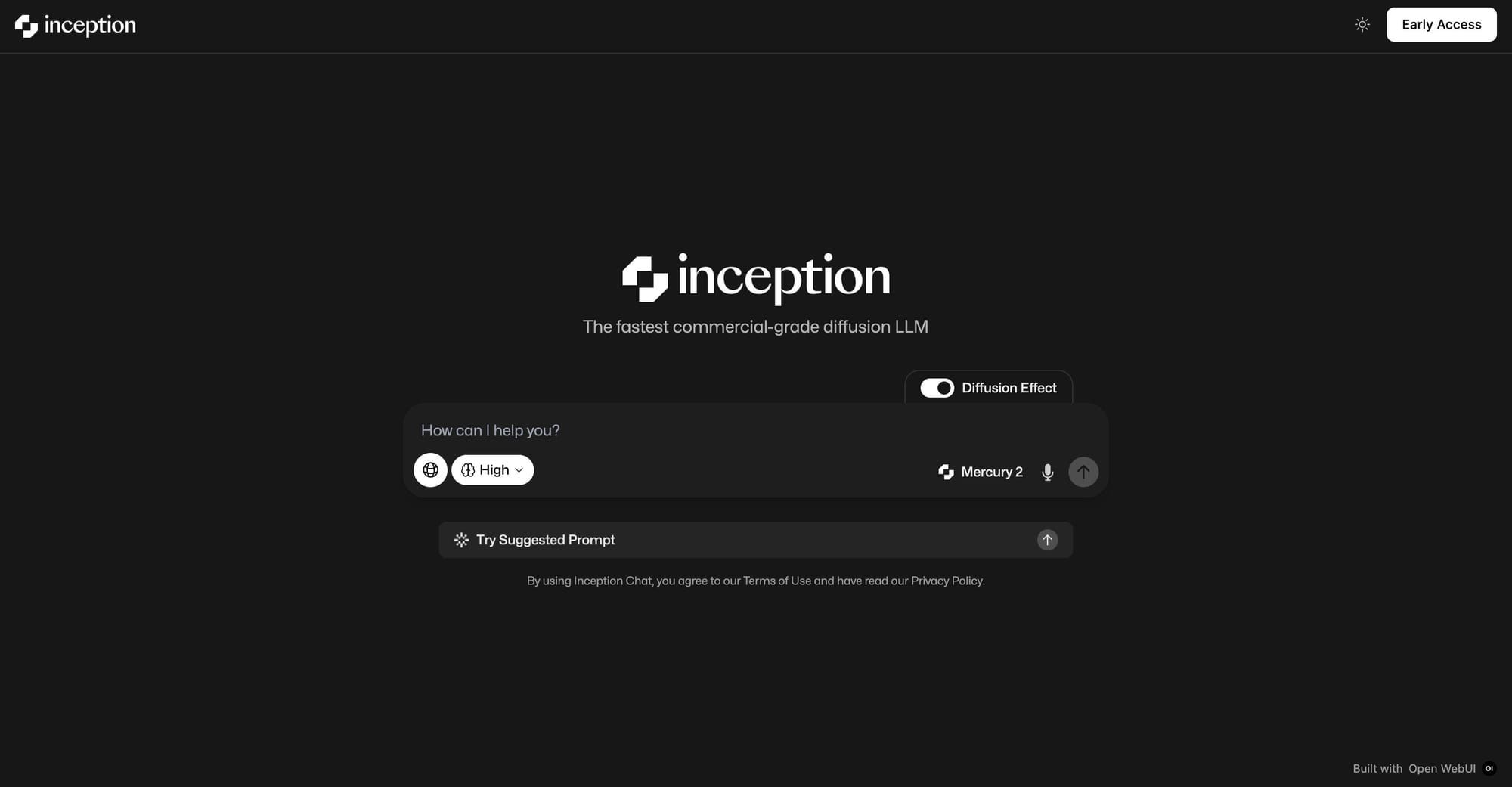
Inception Labs is positioning Mercury 2 as a reasoning-focused model aimed at production systems where latency accumulates across multi-step agent loops, retrieval pipelines, and large-scale extraction jobs. The company’s perspective is that modern AI work is no longer a single prompt and response, making left-to-right token generation the bottleneck that users notice.
Mercury 2 is live 🚀🚀
— Stefano Ermon (@StefanoErmon) February 24, 2026
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting… pic.twitter.com/McrQG4PFLZ
Inception states that Mercury 2 employs diffusion-style text generation instead of autoregressive decoding. According to their description, the model generates and refines many tokens in parallel over a small number of steps, then converges on the final output. The company argues that this approach shifts the usual tradeoff where stronger reasoning requires more test-time compute, which directly increases latency and cost.
In the announcement, Inception lists Mercury 2 at 1,009 tokens per second on NVIDIA Blackwell GPUs, featuring a 128K context window, tunable reasoning, native tool use, and schema-aligned JSON output. Pricing is presented as $0.25 per million input tokens and $0.75 per million output tokens. The company also claims OpenAI API compatibility to support drop-in adoption without major rewrites.
The post also includes throughput comparisons and benchmark-style figures, along with partner quotes focused on lower latency for transcript cleanup and faster automation-style workloads. Inception Labs is building its lineup around diffusion LLMs and presents its team as having contributed to widely used ML techniques and systems work.