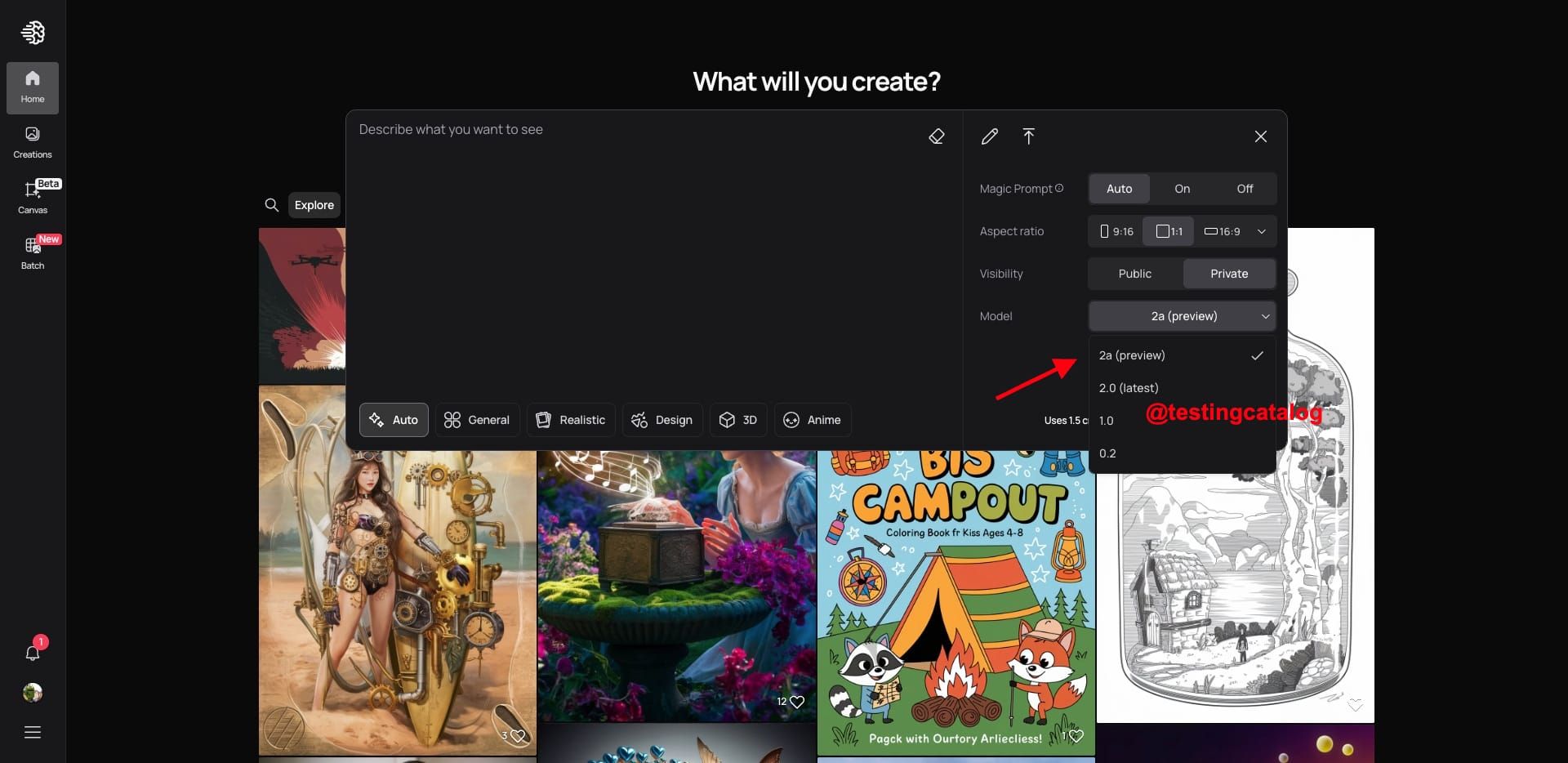
Ideogram's new AI model, version 2.1, is currently in a preview phase. This version builds on the success of Ideogram 2.0, known for its strong performance in text-to-image generation. The key improvement in version 2.1 appears to be its ability to generate consistent text within images, a challenge for many AI models. TestingCatalog shared examples where all four test outputs displayed highly consistent text, marking a potential leap in this area of AI functionality.


Ideogram 2.1 examples
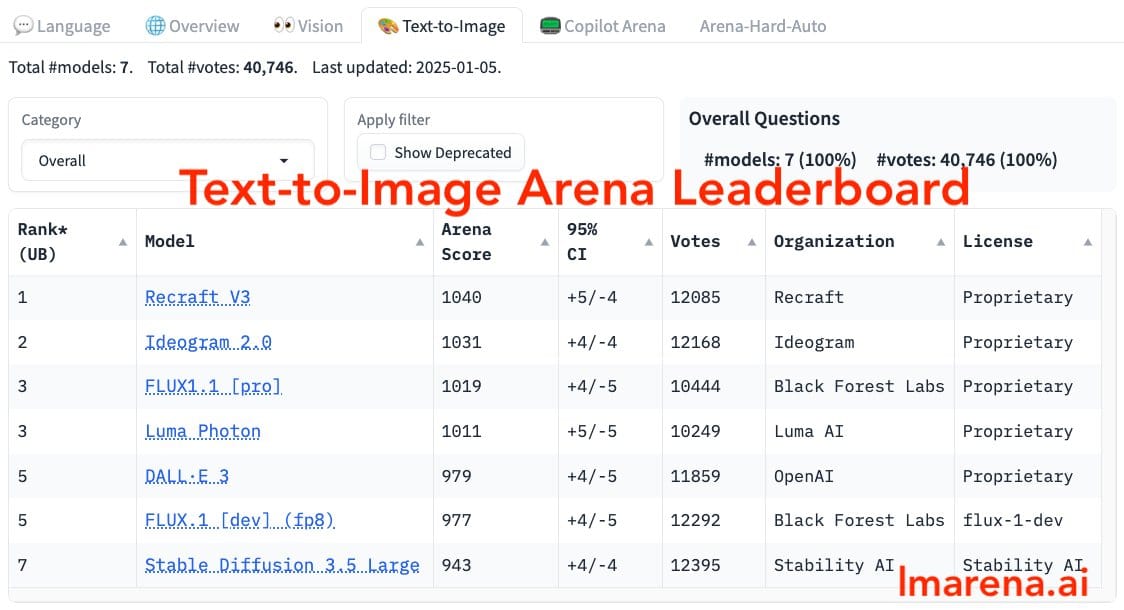
The context provided by lamarena showcases Ideogram 2.0's performance on their leaderboard. It ranked first in the "User Prompts Only" category and third in the "Pre-generated Prompts" category. This suggests that the model excels when users provide creative or specific prompts but faces more competition when working with standardized inputs. The new version, 2.1, is expected to further refine these capabilities, particularly focusing on text consistency within generated images.
While there has been no official announcement about Ideogram 2.1, its development aligns with broader trends in generative AI, where improving prompt adherence and specific-use cases like text-in-image generation are becoming focal points for innovation. This feature could be particularly valuable for industries such as advertising, design, and content creation, where precise text rendering within visuals is essential.
Ideogram's advancements also reflect growing competition in the generative AI space. According to lamarena.ai's leaderboard, other models like Recraft V3 are also performing strongly, indicating a competitive environment where continual improvement is necessary to maintain leadership.
In summary, Ideogram 2.1 represents an incremental but significant step forward in text-to-image AI technology. If officially released with these improvements, it could solidify Ideogram's position as a leader in this niche while addressing one of the most persistent challenges in generative image models: reliable and accurate text integration.





