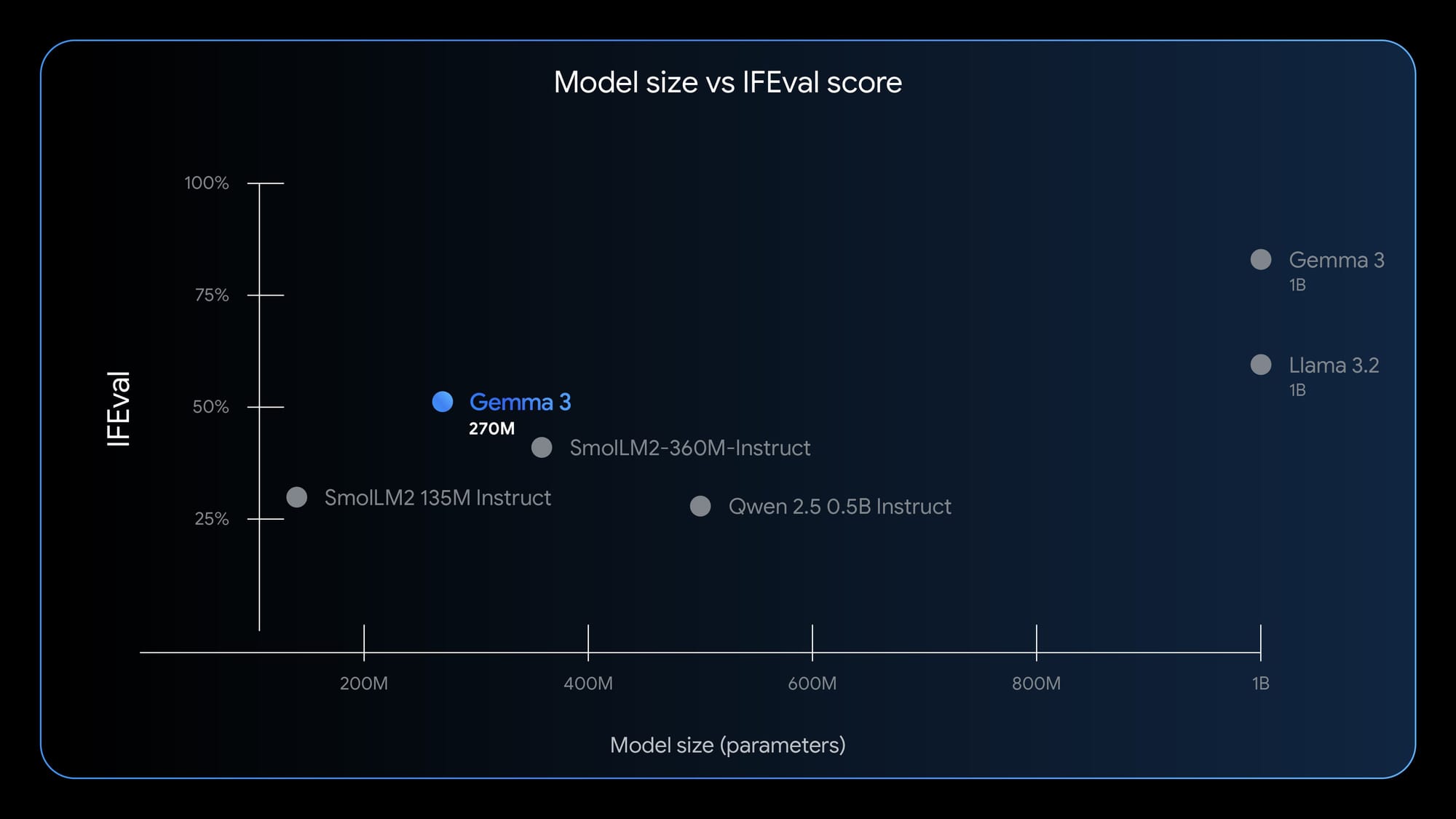
Google has launched Gemma 3 270M today, a 270 million parameter model designed for developers who require task-specific fine-tuning and low-power on-device inference. Internal tests indicate that an INT4 build used only 0.75% of the battery for 25 conversations on a Pixel 9 Pro. This model is aimed at structured tasks rather than long, open-ended chat.
Introducing Gemma 3 270M! 🚀 It sets a new standard for instruction-following in compact models, while being extremely efficient for specialized tasks. https://t.co/kC9OOPwzVi
— Google AI Developers (@googleaidevs) August 14, 2025
The specifications are impressive for its size, featuring a 256k-token vocabulary with 170 million embedding parameters and 100 million in transformer blocks. QAT checkpoints are included, allowing INT4 runs with minimal loss. Both pre-trained and instruction-tuned variants are available. The model is accessible on platforms such as Hugging Face, Ollama, Kaggle, LM Studio, and Docker, with trials on Vertex AI and support in llama.cpp, Gemma.cpp, LiteRT, Keras, and MLX.
An app powered by Gemma 3 270M
Context is crucial for the Gemma 3 family, which handles both text and images. The 270M tier offers a 32K token context window and was trained on 6 trillion tokens. It provides multilingual coverage in over 140 languages, with a training cutoff in August 2024.
The use cases for Gemma 3 270M are clear: classification, entity extraction, query routing, and text structuring. Developers can fine-tune using the new guides and deploy from local hosts to Cloud Run. The model follows instructions well out of the box but is designed to specialize through tuning.
Google DeepMind is expanding the Gemma 3 line following previous rollouts of Gemma 3, Gemma 3 QAT, and Gemma 3n, citing 200 million total downloads last week. Early community demonstrations include a Transformers.js bedtime story app powered by Gemma 3 270M, indicating active uptake by developers.





