
Google has rolled out Gemini 3.1 Flash-Lite, targeting developers and enterprises who require rapid processing and cost-conscious solutions for large-scale workloads. The release is available in preview through the Gemini API on Google AI Studio and for enterprise customers on Vertex AI. This model is tailored for high-frequency tasks and provides a compelling balance of speed, quality, and affordability. At $0.25 per million input tokens and $1.50 per million output tokens, it is positioned as a competitive choice for organizations with substantial data processing needs.
Gemini 3.1 Flash-Lite has landed.
— Google DeepMind (@GoogleDeepMind) March 3, 2026
It’s our most cost-efficient Gemini 3 series model yet, built for intelligence at scale. Here’s what’s new 🧵 pic.twitter.com/BzD2bdg3Dx
Gemini 3.1 Flash-Lite distinguishes itself with a 2.5X faster Time to First Answer Token and a 45% increase in output speed compared to Gemini 2.5 Flash, while maintaining or exceeding quality standards. It posts an Elo score of 1432 on the Arena.ai leaderboard and achieves strong benchmark results, such as 86.9% on GPQA Diamond and 76.8% on MMMU Pro. The model supports advanced reasoning, multimodal understanding, and gives users control over its reasoning depth, making it suitable for diverse tasks like translation, content moderation, and complex data analysis. Early users from companies like Latitude, Cartwheel, and Whering report that Flash-Lite can process complex inputs with precision typically seen in higher-tier models.
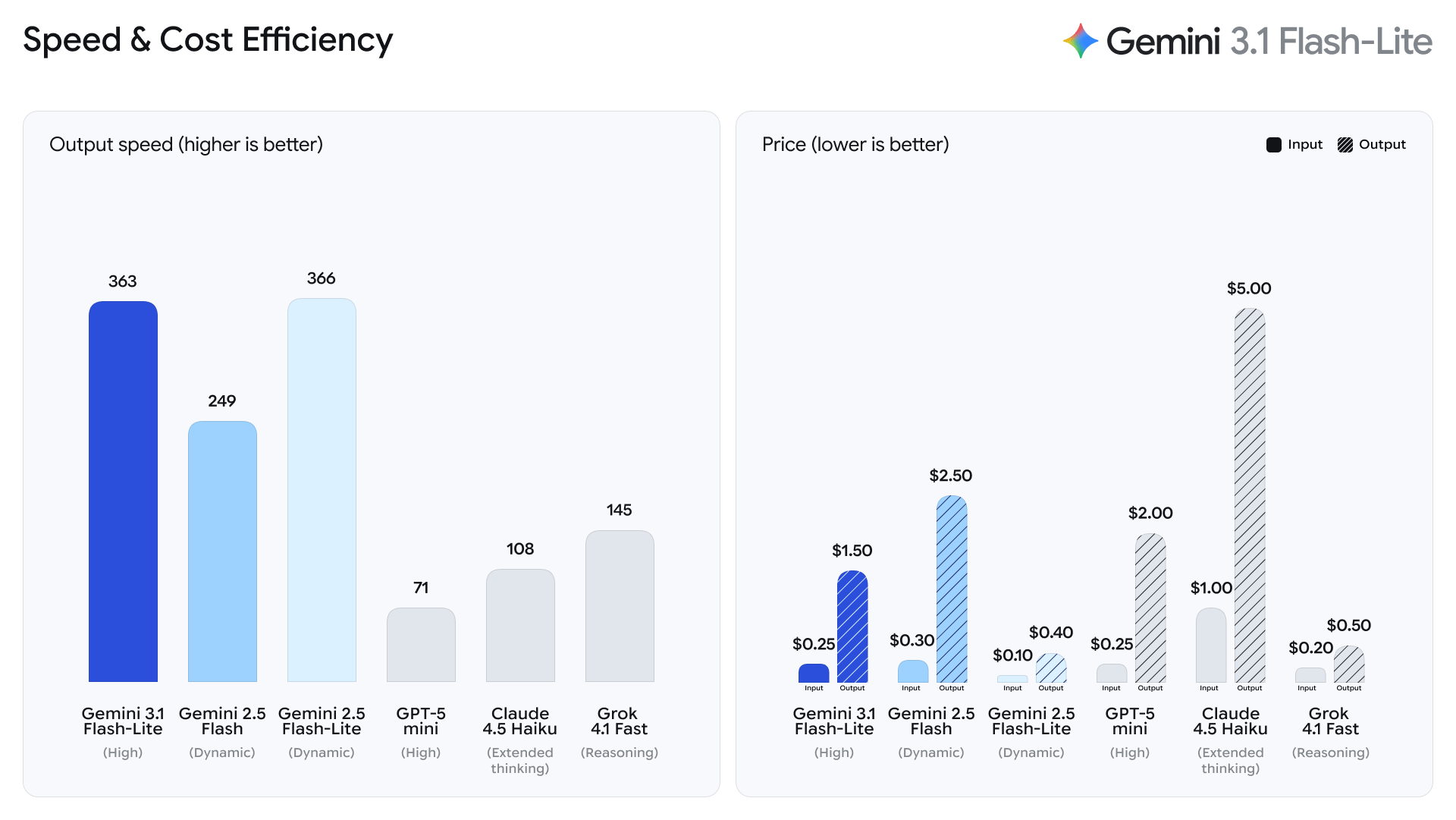
Google, the company behind Gemini 3.1 Flash-Lite, continues to expand its AI offerings with the Gemini 3 series, focusing on delivering scalable and flexible tools for developers and enterprise customers who prioritize performance and efficiency in their applications.





