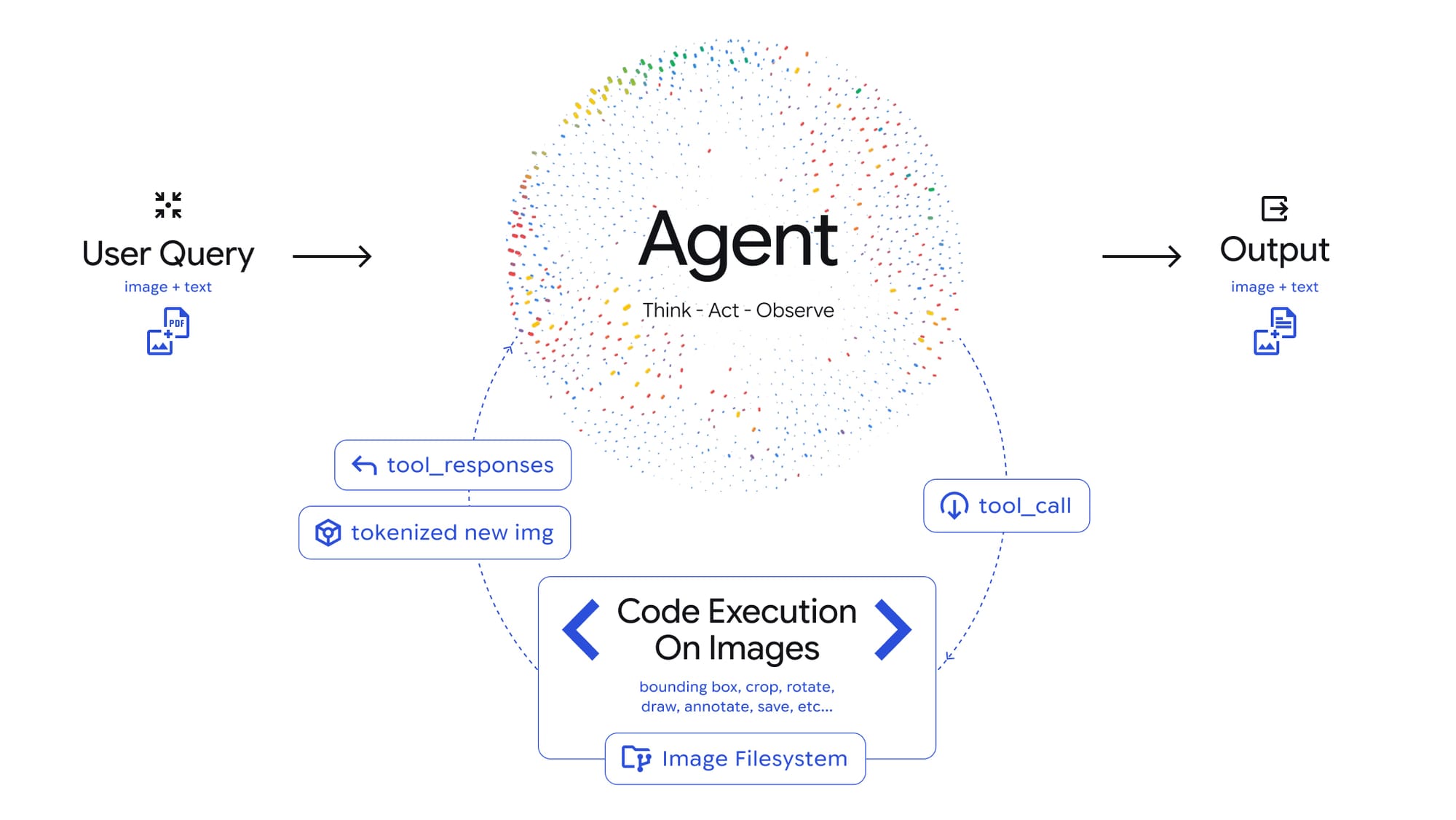
Google has introduced Agentic Vision in Gemini 3 Flash, marking a shift in how AI models perform visual tasks. This release targets developers, businesses, and AI researchers who rely on advanced image analysis and visual reasoning capabilities. The feature is immediately available to users through the Gemini API in Google AI Studio, Vertex AI, and is rolling out within the Gemini app for broader access.
Try 👁 Agentic Vision with Gemini 3 Flash in @GoogleAIStudio or Vertex AI. This new capability enables the model to effectively use code and reasoning to improve performance for common vision tasks.
— Google AI Developers (@googleaidevs) January 27, 2026
See Agentic Vision in action: https://t.co/z0k9VG1YmQ pic.twitter.com/gO5YpAglK5
Agentic Vision transforms image understanding with an iterative approach where the model actively investigates visual inputs. By integrating code execution, Gemini 3 Flash can carry out a Think, Act, Observe loop, analyzing queries, manipulating images with Python code, and using the results to refine its final answer. Key functionalities include:
- Automatic zooming for fine details
- Annotating images
- Parsing complex tables
- Visualizing data with deterministic Python environments
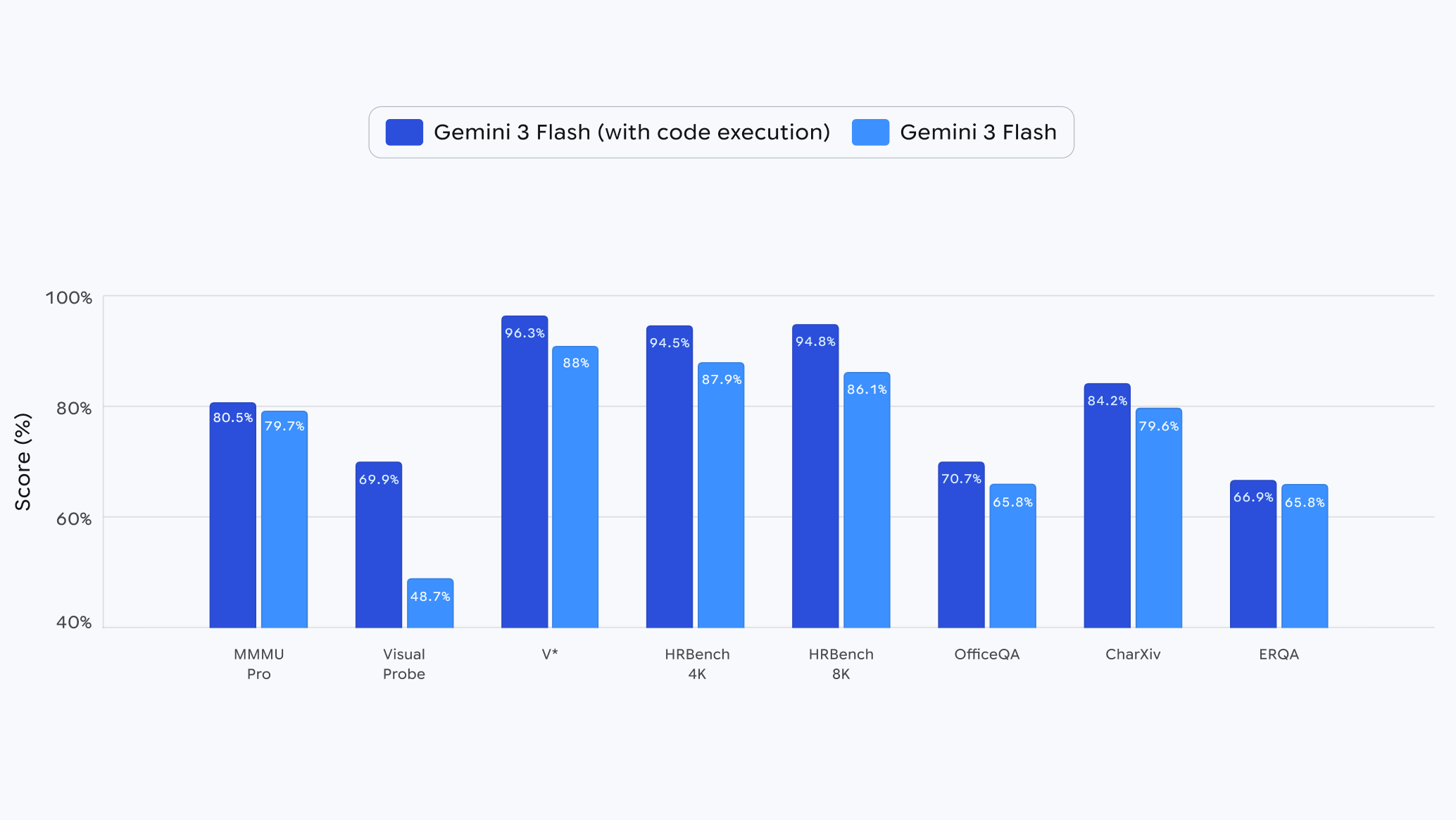
These capabilities provide a consistent 5-10% quality increase across vision benchmarks compared to previous versions, and early users like PlanCheckSolver.com have reported measurable improvements in accuracy for tasks such as building plan validation.
Google is at the forefront of multimodal AI research, and this announcement strengthens its position by enabling its Gemini models to not merely interpret but interact with visual data. The company plans to extend Agentic Vision’s reach by supporting more model sizes and integrating additional tools like web and reverse image search. This latest development underscores Google’s ongoing investment in making its AI models more robust and contextually aware for a diverse set of real-world applications.





