
Cursor has introduced CursorBench-3, the latest version of its in-house evaluation suite designed to measure the real-world performance of coding agents across complex developer tasks. This suite is now used to assess agent solution correctness, code quality, efficiency, and behavior, drawing on actual developer-agent interactions from production Cursor sessions. CursorBench-3 tasks are notably larger in scope compared to previous versions and public benchmarks, often spanning multi-file projects, monorepos, and ambiguous, developer-style requests. The benchmark includes regularly refreshed tasks sourced with Cursor Blame, reducing risks of training data contamination and maintaining alignment with evolving developer workflows.
We're sharing a new method for scoring models on agentic coding tasks.
— Cursor (@cursor_ai) March 12, 2026
Here's how models in Cursor compare on intelligence and efficiency: pic.twitter.com/VItnifMh55
The new benchmark is available internally to Cursor’s engineering and research teams, with evaluation results directly informing product improvements and model deployments for developers using Cursor. Unlike widely-used public benchmarks, CursorBench-3 is tailored for developers who rely on AI agents for increasingly complex software engineering tasks, providing a better gauge of agent utility in actual usage. The company supplements offline evaluations with live, controlled online experiments to capture discrepancies between automated scoring and genuine developer satisfaction.
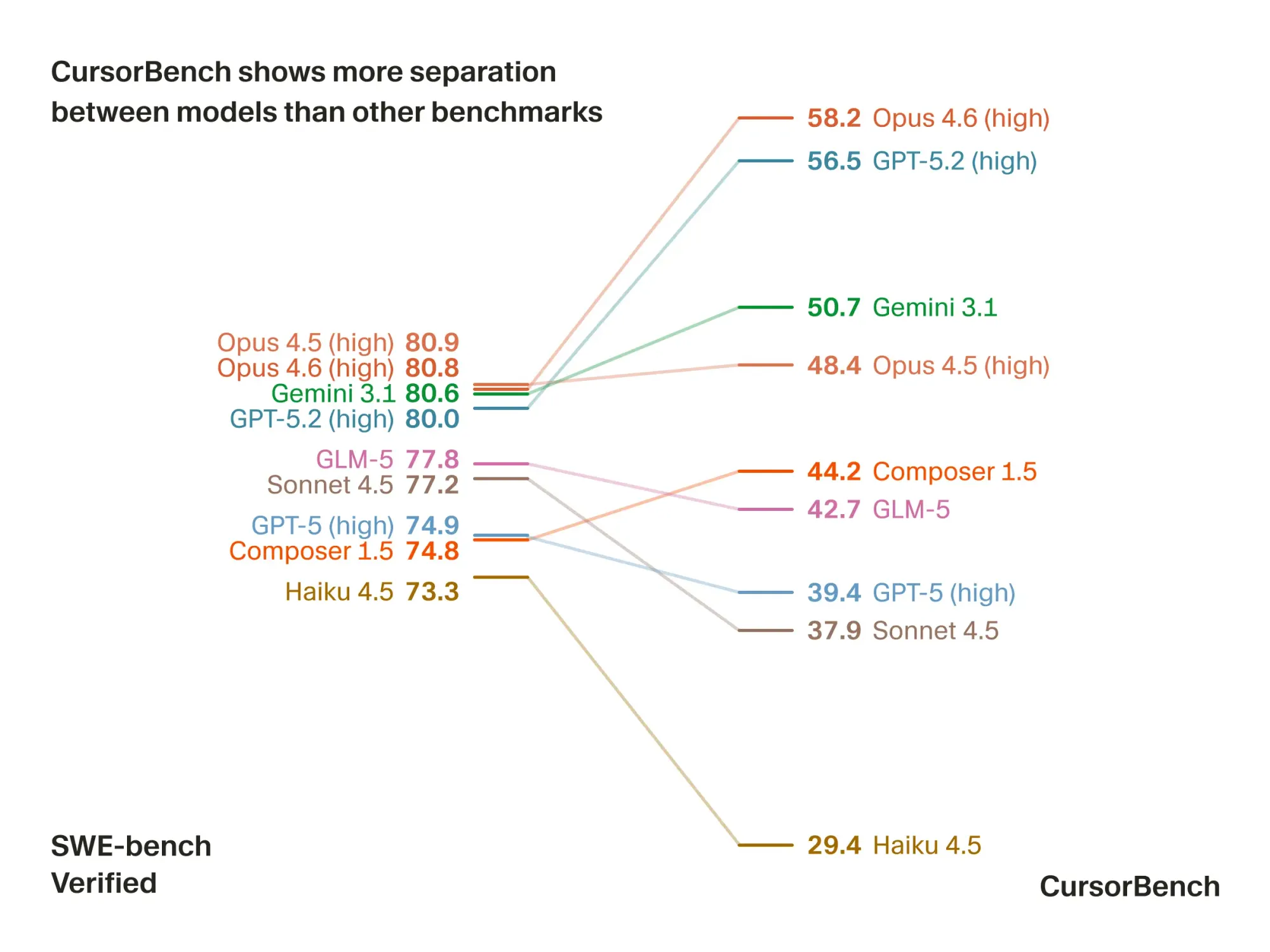
Cursor is focused on delivering AI-powered coding solutions, and this release marks a strategic move to differentiate its agent evaluation process from public and competitor benchmarks, which have shown limitations at the frontier of model performance. The company’s approach aims to keep agent development tightly aligned with real developer needs and to maintain a high standard of code assistance as the complexity of tasks continues to grow.





