
Perplexity has introduced the Deep Research Accuracy, Completeness, and Objectivity (DRACO) Benchmark, positioning it as an open standard for evaluating the capabilities of AI agents in handling complex research tasks. This benchmark is now available to the public, allowing AI developers, researchers, and organizations worldwide to assess their own systems. DRACO is built to reflect authentic research scenarios, drawing its tasks from millions of real production queries submitted to Perplexity Deep Research. It covers ten diverse domains, including Law, Medicine, Finance, and Academic research, and is accompanied by detailed evaluation rubrics refined through expert review.
We've upgraded Deep Research in Perplexity.
— Perplexity (@perplexity_ai) February 4, 2026
Perplexity Deep Research achieves state-of-the-art performance on leading external benchmarks, outperforming other deep research tools on accuracy and reliability.
Available now for Max users. Rolling out to Pro in the coming days. pic.twitter.com/8RAlewuWa3
The DRACO Benchmark evaluates AI agents on four key dimensions:
- Factual accuracy
- Analytical breadth and depth
- Presentation quality
- Citation of sources
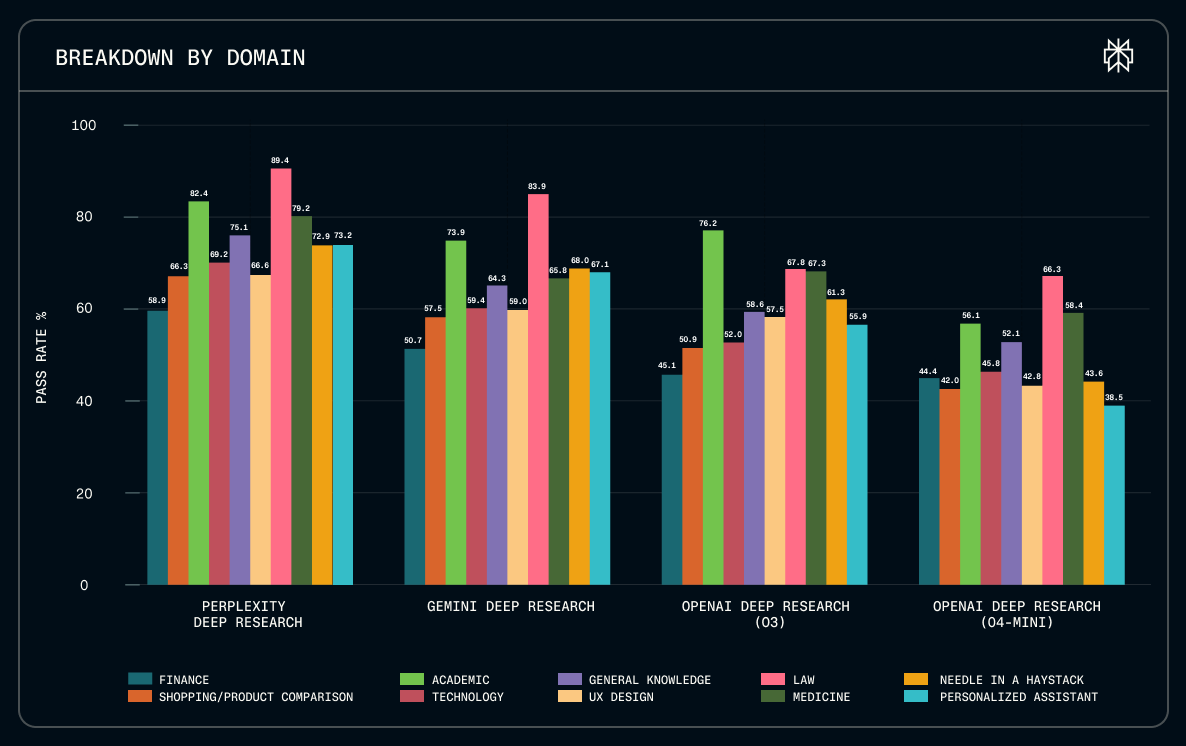
Notably, the evaluation process uses an LLM-as-judge protocol, ensuring responses are fact-checked against real data and reducing subjectivity. Compared to previous benchmarks, DRACO focuses on genuine user needs rather than synthetic or academic tasks and is model-agnostic, so it can assess any AI system with research capabilities. Early results show Perplexity Deep Research leads in accuracy and speed, outperforming competitors in challenging domains such as legal and personalized queries.
Perplexity, the company behind DRACO, is recognized for its AI-driven search and research tools. By open-sourcing DRACO, Perplexity aims to raise the standard for deep research agents and encourage broader adoption of rigorous, production-grounded evaluation methods across the AI industry.





