On May 29, 2025, Hume.ai introduced EVI 3, a third-generation speech-language model built for personalized voice AI. It bundles transcription, reasoning, and speech synthesis, delivering replies in roughly 300 milliseconds.
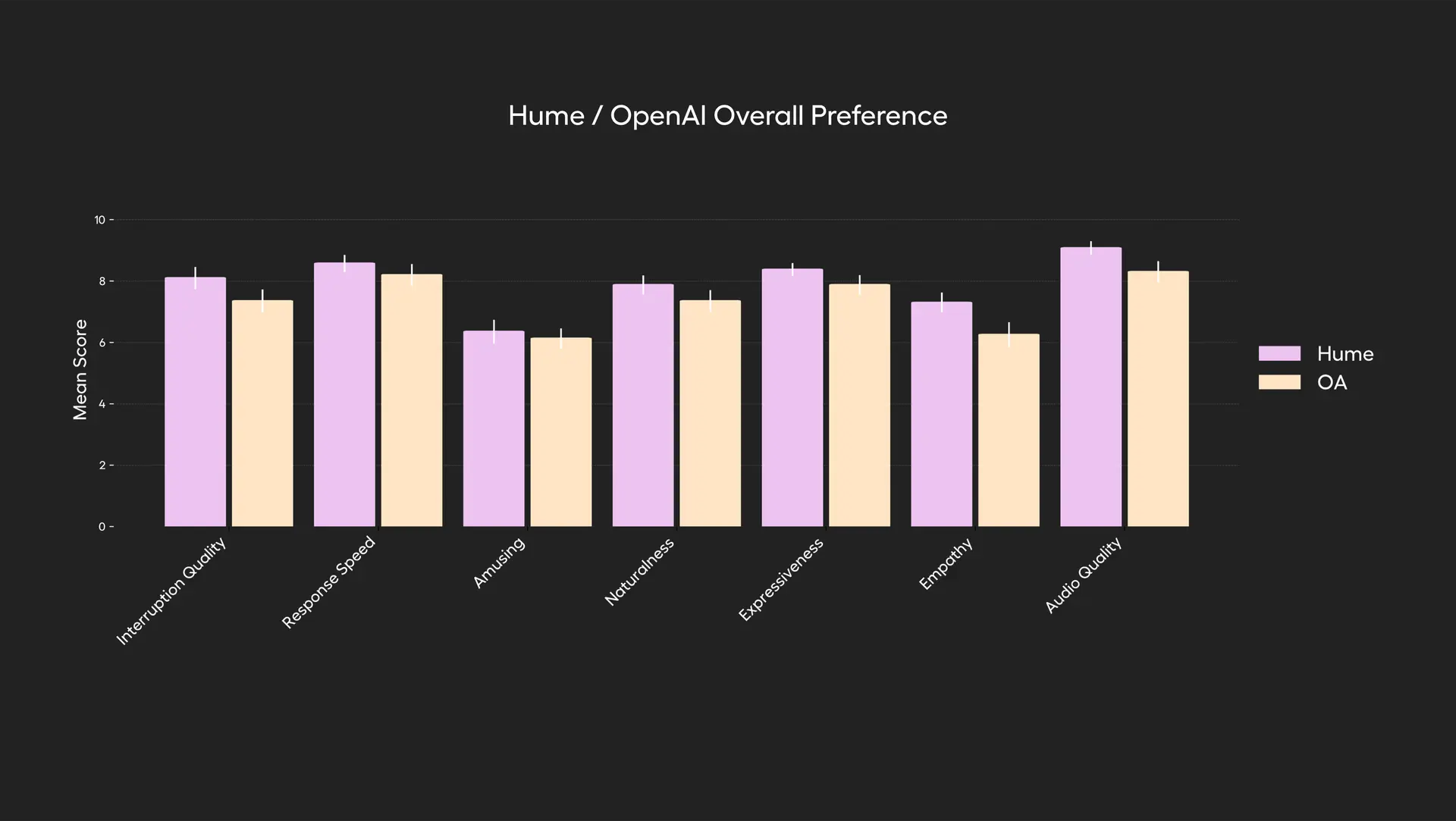
EVI 3 can craft new voices from text prompts by blending elements drawn from 100,000 recorded samples. Reinforcement learning refines pitch, pace, and emotional style, and a mixed text-voice token system lets the model invoke external tools mid-sentence. In blind tests with 1,720 participants, it edged GPT-4o, Gemini, and Sesame in empathy, expressiveness, naturalness, interruption handling, speed, and audio quality. Early demo users report creating custom voices in seconds.
Meet EVI 3, another step toward general voice intelligence.
— Hume (@hume_ai) May 29, 2025
EVI 3 is a speech-language model that can understand and generate any human voice, not just a handful of speakers. With this broader voice intelligence comes greater expressiveness and a deeper understanding of tune,… pic.twitter.com/Sa2YrM2P7A
A public web demo and an iOS companion app are available today, with API access expected within weeks. The model targets customer support, health coaching, gaming, and other voice-heavy domains. Pricing is still under wraps, though the previous generation cost $0.072 per minute. Support for French, German, Italian, and Spanish is slated before full release.
Hume.ai, founded in 2021 by former DeepMind researcher Alan Cowen, trains its models on multimodal datasets of speech and emotion. Earlier milestones include EVI 2 in 2024 and the Octave TTS system released in February 2025, each bringing the company closer to fully adaptive, emotionally aware voice dialogue.





