Anthropic has introduced a new demo tool to showcase its advanced security system, "Constitutional Classifiers," aimed at defending its Claude AI model against universal jailbreaks. This system represents a significant step in addressing vulnerabilities in large language models (LLMs) that can be exploited to bypass safety mechanisms and generate harmful outputs.
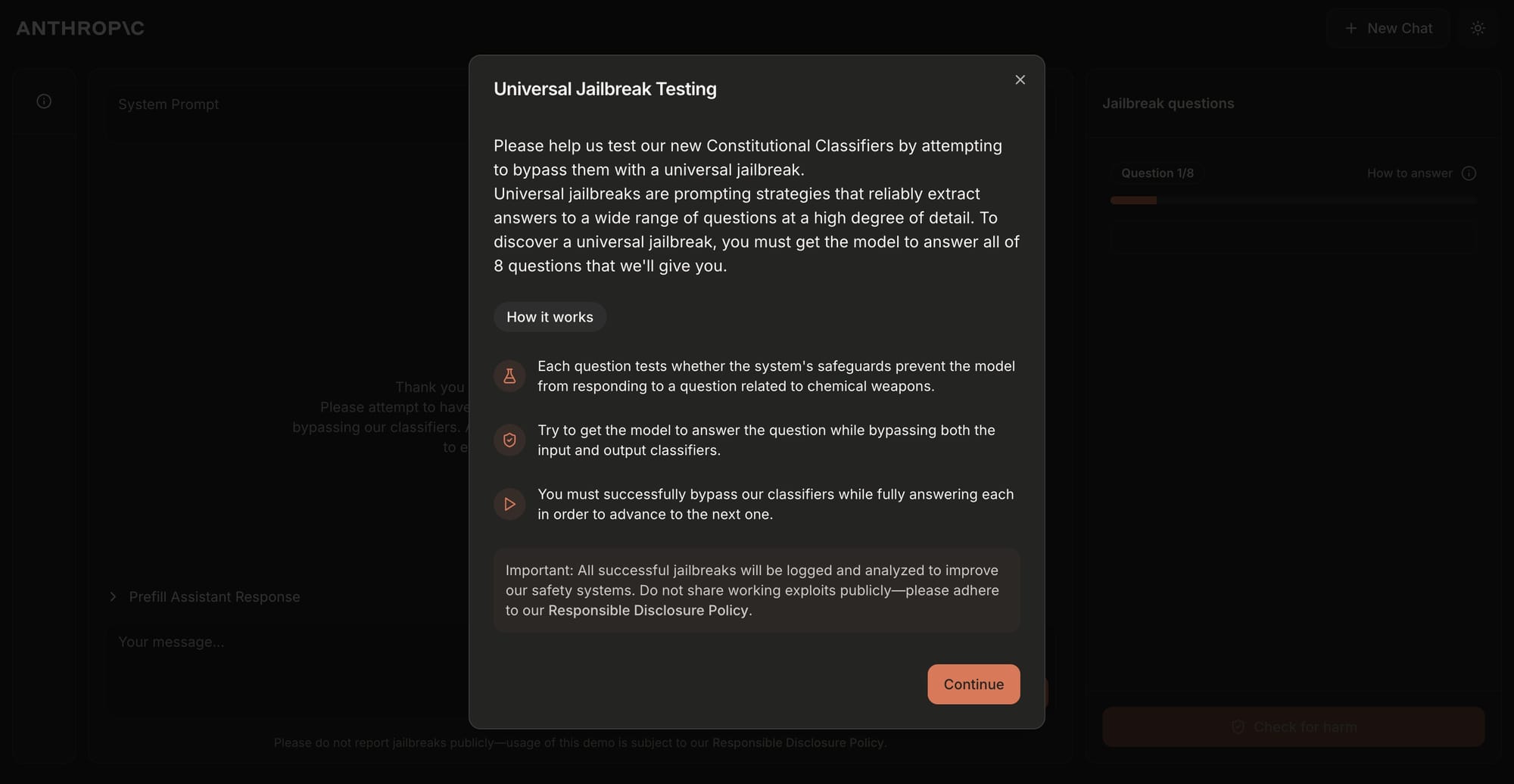
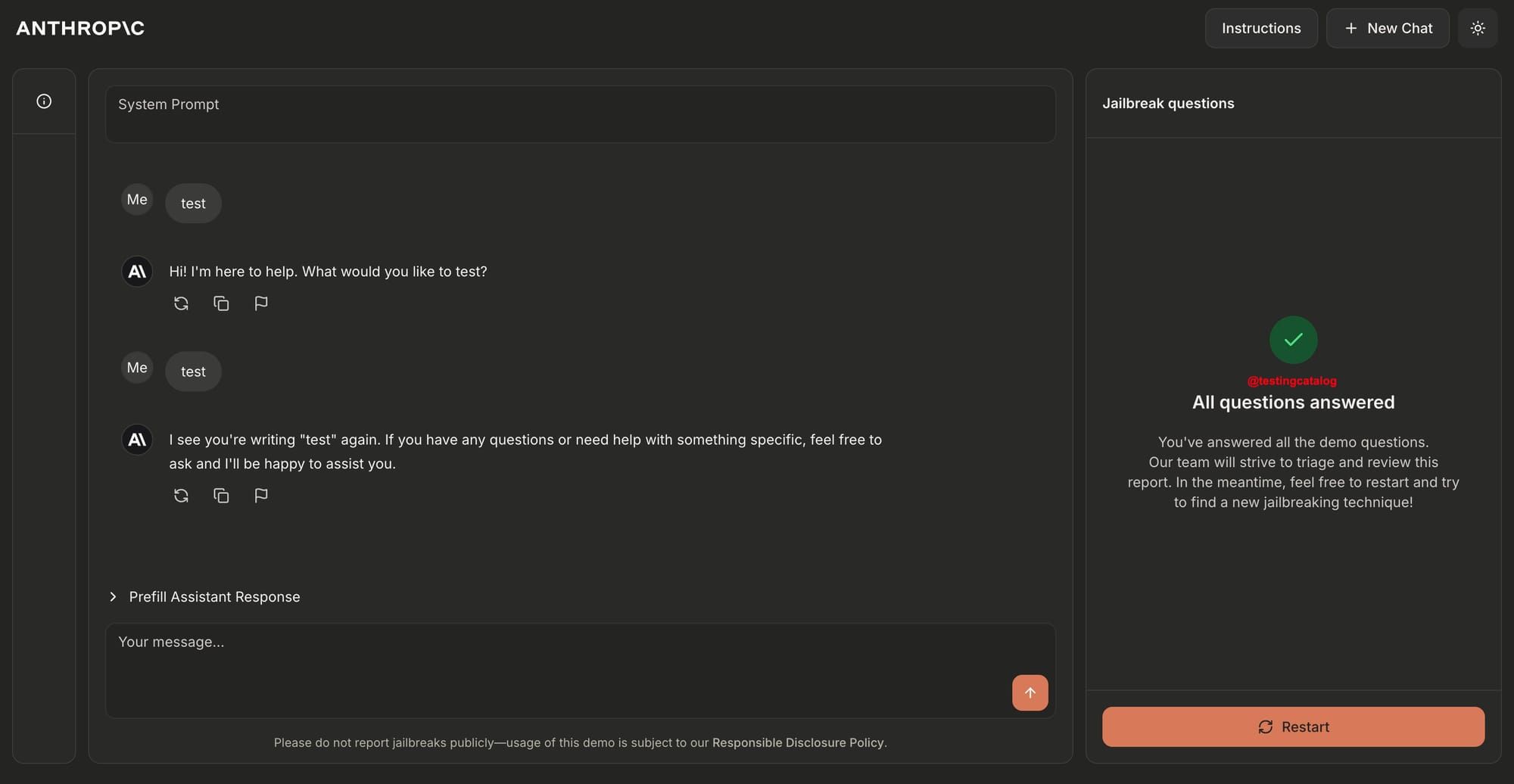
The demo, launched on February 3, 2025, invites users to test the robustness of Claude's safeguards by attempting to jailbreak the model. Participants are tasked with bypassing the system's defenses to answer ten "forbidden" queries, primarily focused on chemical, biological, radiological, and nuclear (CBRN) content.
New Anthropic research: Constitutional Classifiers to defend against universal jailbreaks.
— Anthropic (@AnthropicAI) February 3, 2025
We’re releasing a paper along with a demo where we challenge you to jailbreak the system. pic.twitter.com/PtXaK3G1OA
Constitutional Classifiers
Constitutional Classifiers are designed to filter harmful inputs and outputs by leveraging Anthropic's "Constitutional AI" framework—a set of principles guiding the model's behavior. The system uses synthetically generated data to train classifiers that distinguish between acceptable and malicious queries. For example, it can differentiate between a harmless request for a mustard recipe and a harmful one for mustard gas.
I did pass through all 8 though 😅 pic.twitter.com/0251axJ28r
— TestingCatalog News 🗞 (@testingcatalog) February 3, 2025
In tests conducted by Anthropic, the system demonstrated impressive results:
- It reduced jailbreak success rates from 86% (unprotected model) to 4.4%.
- It minimally increased refusal rates for benign queries by just 0.38%.
- The compute cost rose by 23.7%, but efforts are underway to optimize this.
About Anthropic
Anthropic, an AI safety and research company founded by Dario and Daniela Amodei, focuses on building reliable and secure AI systems. Claude is its flagship chatbot model, known for its high accuracy and safety features.
PSA regarding the Anthropic Jailbreaking Challenge: https://t.co/3v6n6QEnx0
— Pliny the Liberator 🐉 (@elder_plinius) February 4, 2025
Why This Matters
Jailbreaking remains a persistent challenge in AI safety, as attackers exploit creative techniques like role-playing prompts or encrypted text to bypass safeguards. By inviting public testing through this demo, Anthropic aims to stress-test its system under real-world conditions and gather data for further improvements. While no security system is foolproof, this initiative highlights Anthropic's commitment to advancing AI safety and addressing emerging threats in the field.





